Overview of Annotations
The RUEG corpus is a multi-layer corpus of both written and spoken language.
We use several annotation formats in the process of annotation, but all annotations, except for the dependency annotations, are part of the
EXMARaLDA file in the exb directory.
In addition to the editable EXMARaLDA format, the corpus is also converted to the ANNIS format (annis directory) for search and visualization.
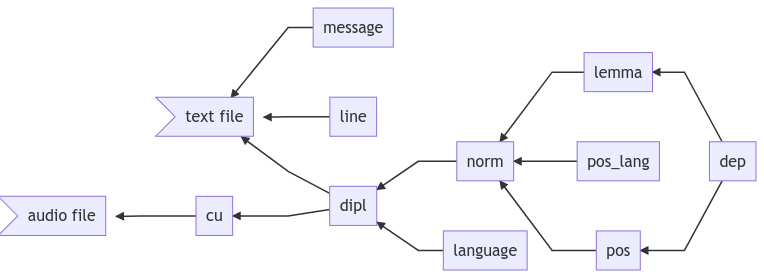
Dependencies between annotation layers
Most annotation layers depend on other annotations. This can to lead to complex dependencies, as visualized by the following graph:
Meta data fields
DISCLAIMER: All sub-1.0 releases may feature inconsistencies in the formatting of the meta data values or show incompleteness of metadata.
In addition to the annotation layers, each document has also meta data fields which are stored in the .meta file next to each EXMARaLDA file.
The meta data is also included in the ANNIS format.
| field name | type | description |
|---|---|---|
| speaker-id | String | |
| formality | String | informal/formal |
| mode | String | spoken/written |
| speaker-bilingual | Boolean | yes/no |
| elicitation-session | Number | 1 (monolinguals, bilinguals in first session) 2 (bilinguals in second session) |
| elicitation-language | String | Language that is elicited from the speaker |
| elicitation-country | String | |
| elicitation-order | Number | 1-8 |
| elicitator-good-id | String | project- and people-number of "good cop" |
| elicitator-bad-id | String | project- and people-number of "bad cop" |
| elicitation-date | String | 2018-XX-XX |
| transcriber-id | String | comma-separated list of project- and person-number XX-XX |
| normalizer-id | String | comma-separated list of project- and person-number XX-XX |
| annotator-id | String | comma-separated list of project- and person-number XX-XX |
| speaker-language-s | String | Languages as given by the participants and separated by comma |
| speaker-age-group | String | children/adolescents/adults |
| speaker-gender | String | m/f/d |
| speaker-age | Number | two-digit number year |
| speaker-AoO | Number | Age Of Onset in years (two-digits) |
| speaker-AoO-answer | Number | complete, but anonymized answer string |
| speaker-personality-score-X | Number | Personality score (1-7) for each of the questions 1-6 of the personality test |
| speaker-extravert-score | Number | aggregated extravert score |
Meta data fields new in 0.3.0
| field name | type | automatically retrievable from questionnaire | description / comments |
|---|---|---|---|
| speaker-region-of-birth | String | text value only | This and the following meta key are retrieved as place of birth, from which you are supposed to extract the region (e. g. "Bavaria", "North Carolina", "Krasnoyasrk", "Aegean Islands", "Central Anatolia", you might prefer the term federal state or province ) and/or the country. For privacy reasons please do not provide the city or even more detailed information. |
| speaker-country-of-birth | String | text value only | See above. |
| speaker-age-of-immigration | Number | yes | Age of arrival in country of majority language in years. Single digit. For the age in years and months, use one of the following options: for instance, for 3 years 6 months, you can write 3.5 or 3;6. |
| speaker-education-degree | String or Number | yes | Categorical values, provided by questionnaire. Please be careful with the adolescents: many of them selected high school as their highest degree completed but in fact they did not complete it yet. So we need to look at "grade. School year" to see if the adolescent is in high school or in college. |
| speaker-employment | String | yes | Categorial values, provided by questionnaire. |
| speaker-dialect-s | List of strings | yes | List of dialects spoken (comma-separated). |
| speaker-language-instructed-1 | String | yes | A language the participant was instructed in. More languages possible (2, 3, ...). |
| speaker-language-instructed-1-duration | Number | no | Number of YEARS (other unit prefered?) the participant was instructed in language 1. As with the fields concerning age, you can write 3.5 or 3;6. |
| speaker-parent-1-... | |||
| speaker-parent-2-... | |||
| speaker-parent-3-... | |||
| speaker-parent-4-... | |||
| speaker-parent-1-name | String | yes | "Mother", "Father", "Sister", "Brother", etc. Capitalization does not matter, leave the words as they were originally written. Needs to be anonymized. |
| speaker-parent-1-country-of-birth | String | textual value | Please extract the name of the country from the given answer. Delete any more precise information. |
| speaker-parent-1-region-of-birth | String | textual value | Please extract the name of the region from the given answer. Delete any more precise information. |
| speaker-parent-1-degree | String or Number | yes | As above, highest degree, but for parent / adult. |
| speaker-parent-1-profession | String | yes | Profession of parent / adult. |
| speaker-parent-1-employment-institution | String | yes | Current employment (institution, category) of parent / adult. Might need anonymization. Note that sometimes only position or institution is derivable from the answer, so n/a should be used for unavailable meta values. |
| speaker-parent-1-employment-position | String | yes | Current employment (position, category) of parent / adult. Might need anonymization. Note that sometimes only position or institution is derivable from the answer, so n/a should be used for unavailable meta values. |
| speaker-parent-1-language-home-1 | String | yes | Language spoken at home by parent / adult (to anybody). Capitalize the language!! |
| speaker-parent-1-language-home-2 | String | yes | Language spoken at home by parent / adult (to anybody). |
| speaker-parent-1-language-home-3 | String | yes | Language spoken at home by parent / adult (to anybody). |
| speaker-parent-1-dialect-s-home | List of strings | yes | Dialects spoken at home by parent / adult (to anybody). Capitalize the dialect!! |
| speaker-env-1-... | Those values are for adults in current environment, but also include the parents again. | ||
| speaker-env-2-... | Therefore we might not have to use all of them. | ||
| speaker-env-3-... | All values meta fields for parents have to be repeated for adults in environment. | ||
| speaker-env-4-... | |||
| speaker-shares-home-with-env-1 | Boolean | Whether or not the speaker lives together with the respective adult in their environment. | |
| speaker-shares-home-with-env-2 | Boolean | ||
| speaker-shares-home-with-env-3 | Boolean | ||
| speaker-shares-home-with-env-4 | Boolean | ||
| speaker-frequency-of-visits | String | as text | How often the participant visits the country where the heritage language is spoken. |
| speaker-self-assessment-hl-oral-understanding | String or Number | yes | Self assessment by participant of oral understanding in heritage language. |
| speaker-self-assessment-hl-written-understanding | String or Number | yes | Self assessment by participant of understanding of written text in heritage language. |
| speaker-self-assessment-hl-oral-production | String or Number | yes | Self assessment by participant of oral production skills in heritage language. |
| speaker-self-assessment-hl-written-production | String or Number | yes | Self assessment by participant of written production in heritage language. |
| speaker-self-assessment-hl-native | Boolean | yes | Does the participant consider him-/herself a native speaker of the heritage language. |
| speaker-languages-used-regularly-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks regularly to adult 1 (environment). |
| speaker-languages-used-often-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to adult 1 (environment). |
| speaker-languages-used-rarely-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks rarely to adult 1 (environment). |
| ... | |||
| speaker-languages-used-regularly-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks regularly to parent 1. |
| speaker-languages-used-often-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to parent 1. |
| speaker-languages-used-rarely-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to parent 1. |
| ... | |||
| parent-1-languages-used-regularly-to-speaker | |||
| parent-1-languages-used-often-to-speaker | |||
| parent-1-languages-used-rarely-to-speaker | |||
| env-1-languages-used-regularly-to-speaker | |||
| env-1-languages-used-often-to-speaker | |||
| env-1-languages-used-rarely-to-speaker | |||
| ... | |||
| speaker-habits-video-consumption-hl | String | yes | How often does the participant consume videos in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-audio-consumption-hl | String | yes | How often does the participant consume auditive media in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-text-production-hl | String | yes | How frequently does the participant produce text in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-text-consumption-hl | String | yes | How often does the participant read in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-uses-native-script | String | as text | This needs some additional thought. A textual answer is delivered an we still need to think of useful value set. P2: we are replacing unhelpful answers like "script", "keyboard", and "alphabet" with* n/a.* |
| speaker-habits-messenger | String | yes | Which text messenger does the participant mostly use. |
| speaker-habits-activities | String | yes | Which activities does the participant exercise. Needs privacy check, could maybe be dropped and only languages are kept. |
| speaker-habits-activity-language-s | String | yes | Languages used during those activities. |
| elicitation-ease-formal | Boolean | yes | Was it easy for the participant to image herself in the formal situation. |
| elicitation-ease-informal | Boolean | yes | Was it easy for the participant to image herself in the informal situation. |
| elicitation-issues-with-smartphone | Boolean | yes | Did the participant face any issues dealing with the smartphone during elicitation. |
| elicitation-issues-with-smartphone-text | Boolean | yes | Text answer describing the issues with the smartphone. Empty if no issues occured. |
| speaker-habits-smartphone-type | String | yes | Not sure that is necessary, but we have it. |
cu (Communication Unit)
Value set: open
Segmentation and transcription of Communication Units For spoken data, the start and the end of the CUs are manually aligned with the audio.
See the transcriptions guidelines for details.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | manual | Transcription | exb |
dipl (Tokenization)
Value set: open
Automatic tokenization of the text into words.
- as defined by the TreeTagger tokenization script
- extra handling for emojis and pauses
Language-specific differences
- language specific abbreviations
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | TreeTagger | exb |
norm (corpus-wide normalization)
Value set: open
A common normalization that is the same for written and spoken data. This allows a search across registers.
- segmented into graphemic words
- emojis are a single word
- text messsage acronyms are treated as single word
- punctuation is considered a token if not part of an emoji
- following standard orthography
- no word order corrections
- no grammatical corrections
Language-specific differences
- script is normalized to language standard
- each language decided on
- orthographic standard
- clitics
- script
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Copy base text | exb |
| 2 | manual | Normalize | exb |
lemma (Lemmatization)
Value set: open
Lemmatization based on the normalization (norm).
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | lemmatization (part of the POS-tagging) | exb |
| 2 | manual | correction | exb |
pos (Universal part of speech)
Value set: closed
Part of speech annotation using the Universal POS tags.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Automatic POS tagging | exb |
pos_lang (Language specific Part of speech)
Value set: closed
Part of speech annotation with a tag-set for each language.
- there is one common tag-set for each language
- text message acronyms get their own tag manually (or if the tagger supports it, automatically)
Different tagsets are used for each language:
| language | tag set | reference |
|---|---|---|
| English | British National Corpus / Claws 4 | Leech et al. 19941 |
| German | STTS 2.0 | Westpfahl 20142 |
| Russian | MyStem tag set | Segalovich 20033 |
| Turkish | MULTILIT tag set | Schroeder et al. 20154 |
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Automatic POS tagging with tool | exb |
| 2 | manual | correction | exb |
language (Language/Foreign Material)
Value set: closed
Describes the language.
- per-token
- ISO three letter language code
- every token has this category assigned
- no dialects
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Fill out default language | exb |
| 2 | manual | Mark foreign material | exb |
message (Chat Message span)
Value set: natural numbers
Span annotation for each message in the chat. Contains its consecutive number.
line (Chat Message line)
Value set: open
Span annotation with the chat message text as content.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | exb |
dep (Universal Dependencies)
Value set: closed
Automatic Universal Dependency parsing.
Processing steps
| # | type | step | output format | |
|---|---|---|---|---|
| 1 | automatic | UD Parsing | CoNLL |
Leech, Geoffrey, Roger Garside, and Michael Bryant. 1994. “CLAWS4: The Tagging of the British National Corpus.” In COLING 1994 Volume 1: The 15th International Conference on Computational Linguistics. Vol. 1.
Westpfahl, Swantje. 2014. “STTS 2.0? Improving the Tagset for the Part-of-Speech-Tagging of German Spoken Data.” In Proceedings of Law Viii-the 8th Linguistic Annotation Workshop, 1–10.
Segalovich, Ilya. 2003. “A Fast Morphological Algorithm with Unknown Word Guessing Induced by a Dictionary for a Web Search Engine.” In MLMTA, 273–80. Citeseer.
Schroeder, Christoph, Christin Schellhardt, Mehmet-Ali Akinci, Meral Dollnick, Ginesa Dux, Esin Işil Gülbeyaz, Anne Jähnert, et al. 2015. “MULTILIT.” Universität Potsdam. https://publishup.uni-potsdam.de/opus4-ubp/frontdoor/index/index/docId/8039.
Annotation Step 1: Transcription
Anonymisation
Anonymisation on Speaker tier
-
Replace name of participant with the respective speaker code, e.g. USbi02FR
-
If whole names or surnames of friends are mentioned, replace with the participant code + _P, e.g. USbi02FR_P
-
Places that could lead to the identification of a participant, like streetnames, schoolnames, etc.:
- "Friedrichstraßezzz", you transcribe as "{streetname}Straße". "zzz" has to be replaced by any inflectional suffixes/erase it if there are no such suffixes
- "Apple Highschools“ (with plural suffix), you transcribe as "{schoolname}schools".
! Attention: There should be no spaces following the {...}. ! Over time a list of these placeholders should be developed by every project
Segmentation
- Communication Unit (CU) is used as a segmentation unit
- No punctuation marks at all on the transcription layer
- No accents, no intonation patterns are marked
- In Exmaralda: blank space at the end of each event (* no punctuation marks on norm layer)
Our decisions to CU segmentation you find here: Decisions CU Segmentation
Spelling
- No capital letters
- Abbreviations/acronyms are transcribed as full words in the phonology of the language heard in the recording(e.g. German BMW = beemwe, English BMW = beemdoubleyou)
- speaker codes need to be partly capitalized to follow their correct pattern
Transcription
Adapted from KiDKo2014
'Unwanted' material
- 'unwanted' material are questions of participants concerning the procedure and eventual responses from the elicitator
- first, figure out if you can exclude this kind of data with 'unwanted' material and repeat the elicitation
- If this is not possible, mark those passages as:
<Q> communication with elicitor </Q> - they get an extra-event
Merged forms
- Merged forms are transcribed as they are articulated, but with an equal sign linking the merged elements
- Examples: so=ne (= so eine)
Reduced syllables
- reduced syllables are transcribed as articulated
- Examples: goin (= going), bi tane (= bir tane), hab ich ein Tadel bekommen (= einen Tadel)
Elisions, repetitions and interruption
- Do not leave anything out and do not add anything which is not there!
- Use / to mark unfinished words, e.g. “The bl/ blue car crashes um stops“
- word internal cancellations/corrections are transcribed as follows: dipl: "be$ha$ come" (norm: "become")
- Onomatopoeias/echoisms are separated tokens (e.g. gutschi gutschi gutschi), only transcribed as one single token if they are very short (e.g. eieiei)
Pauses
- always measured to the first decimal
- 0.2 - 1 sec: (-)
- 1 - 3 secs: (--)
- More than 3 secs: (5.5) to be measured
- Wordinternal pauses are marked as followed: be(-)have 1
- keep in mind that there might be persons who talk really slowly (makes no sense to put a pause after every word/token)
- pauses inside a CU do not get an extra-event on the CU tier
- pauses which occur between two CUs get an extra-event on the CU tier
Long vocals & consonants
- vocals realized longer than normal (0.2 - 2sec) are marked with : (e.g. so lo:ng)
- vocals that are realized longer tha 2 seconds are marked with :: (z.B. so lo::ng)
- also possible for consonants (e.g. mum:)
- doubling of vocal syllables with % (e.g. by%ye, tschü%üß)
Non-verbal material
- non-verbal events such as a participant laughing or coughing are noted in square brackets on the transcription tier, e.g. [laughing]
- if participants speak and laugh at the same time, you note it as: [[laughing]speech]
List of meta comments used in the RUEG project
- [coughing]
- [gulping]
- [laughing]
- [pfing] for a sound like "pfff"
- [sighing]
- [throatclearing]
- [tongueclicking], including tsking as disapproval, while thinking and just mouth opening with a click
- [whispering]
- [stuttering]
- [imitating], for when they imitate a sound related to the story (e.g., car crash)
- [sniffing]
Uninterpretable material
- uninterpretable material is to be marked as (UNK) on Speaker-tier
- longer than 2secs: (UNK, 2.1)
- assumed content is placed in between brackets, each token separated: (assumed) (content)
- if the uninterpretable material can be identified as belonging to a CU, there is no seperated event on the CU tier for it
Hesitation markers / Interjections / Reception markers
- For every language, we define a set of hesitation markers/interjections/reception markers
- create a list with those markers
- If heritage speakers use particles from their ‘other’ language, we transcribe them as they sound, consistent with the procedure on foreign language material2
Foreign language material
- Choose a spelling for each item following one of those options:
- transcribe phonographically (e.g. engl. like = germ. leik) OR
- use orthographic spelling of the "other" language
- Create a list where you document the spelling of each item in alphabetic order
- put the file name that includes the word and the time of the appearance in the list
- each time you encounter foreign language material in your data, check the list to guarantee a consistent form for those items3
Proper/Brand names from "foreign language"
- Keep conventionalized spelling (e.g. Renault = renault)
- document your decisions, create a list with those items
- Language specific decisions: Russian: put it in the spelling and script of the actually spoken language to avoid loss of phonetic/morphological/syntactic information Turkish and Greek: use Latin alphabet and conventionalized spelling
Table of symbols
| Symbols | Meaning |
|---|---|
<Q> communication with elicitor </Q> | instances of questions concerning the procedure and/or verbal interventions of elicitators |
| (-) | pauses up to 1sec |
| (--) | pauses 1-3secs |
| (3.2) | pauses longer than 3secs |
| (UNK) | uninterpretable material |
| (UNK, 2.2) | uninterpretable material longer than 2secs |
| (assumption) | assumed material |
| [...] | non-verbal material |
| [[...]...] | non-verbal & verbal event |
| : | unusually long vocal or consonant (under 2secs) |
| :: | unusually long vocal or consonant (longer than 2secs) |
| = | merged forms |
| / | interruption of a word |
| $...$ | word internal cancellations |
| % | doubled syllables |
| {...} | specification of an anonymised place |
Annotation Step 2: Normalization
Segmentations in our corpus
Our corpus pipeline faces 4 types of input for each speaker that participated in the elicitation:
- formal written (fw) text files
- informal written (iw) chat exports
- formal spoken (fs) transcriptions
- informal spoken (is) transcriptions
All data types are divided in above-word-level ("phrasal") segments:
- fw: sentences indicated by punctuation used by the participant
- iw: messages and lines indicated by separators used by the participant (punctuation, new line, message separation)
- fs and is: communication units (CUs) indicated by transcriber (some projects might use intonation phrases additionally)
We annotate our CUs on the annotation tier "cu" (in lowercase letters). These segments are then automatically tokenized (roughly speaking divided in character sequences between two whitespaces), which provides our first word-level segmentation: The diplomatic layer, consisting of graphemic words represented in the phrasal segments.
This word-level segmentation is then to be normalized to facilitate search and automatic annotation.
What is normalization in our corpus and what is its purpose
The result of normalization is an additional word-level segmentation layer, similar to dipl. Starting at the diplomatic tokenization, explicit rules are to be applied to obtain orthographically normalized tokens on the norm layer. Starting of as a copy of the diplomatic token layer, the normalized tokens can (but do not necessarily need) to undergo operations such as edition, deletion, split or merge.
Underlying principles and things to keep in mind
-
Our normalization is not the last step of analysis and does not remove information from the overall corpus
-
Normalization takes place mainly on word-level to obtain standardized forms w.r.t. an orthography of reference
-
We will agree on an orthography of reference for each language in our corpus
-
The normalized layer uses the language's native script, whereas the diplomatic layer sticks to the script used by the participants for the written registers (fw, iw)
-
We do not normalize syntax. This way we are able to learn about an underlying grammar more easily rather than analysing the elicitated language in terms of a standard grammar. Note that this comes with disadvantages but is more appropriate for our projects' idea. We want to obtain a layer that is orthographically normalized but still allows to do syntactical analyses. This is why we do not normalize syntax and try to keep as many elements as possible.
-
Normalization is also a technically necessary process. Orthographically standardized forms help all researchers, those not familiar with our data included, to search linguistic phenomena. Furthermore, annotation to be integrated in our corpus can be pre-generated automatically and efforts of correction are reduced.
-
The highest priority is to ensure that we will always be able to answer our research questions.
-
We do not alternate lexical choice when normalizing.
-
The norm layer will enable us to identify grammatical units.
-
A normalization decision is always influenced by the question of how controversial and/or lossy in terms of information that decision might be.
-
Since this is our first layer of normalization, we normalize very carefully.
-
There will be no grammatical normalizations (adaption of cases or gender or other grammatical features that deviate from our understanding of "standard")
-
We normalize to a single standardized form (if possible) to reduce noise in the tokenization
-
We always normalize as far as we can go, which means we are more careful in some cases compared to others. As an example, 're stays 're in the normalization, because tempus is unclear, whereas 'll can be normalized to will, since it is entirely uncontroversial what the diplomatic form expresses.
-
When normalizing, we try to be as uninterpretative as possible.
-
1:1 mappings from diplomatic and normalized tokens are easier to decide on, because the alternation in the form is easy to trace.
-
The standardized representation should be influenced by the underlying orthography explicitly and implicitly, e. g. for German clitics we do not use an apostrophe in the separated token, whereas we do for English.
-
Normalization should not alternate meaning (if possible).
Orthography of reference
| language | orthography of reference | reference |
|---|---|---|
| English | American English | Merriam-Webster |
| German | „Neue deutsche Rechtschreibung“ | Amtliche Regelung der dt. Rechtschreibung, Duden |
| Greek | Standard Modern Greek | Λεξικό της κοινής νεοελληνικής and David Holton, Peter Mackridge, Irene Philippaki-Warburton (1997) Greek: A Comprehensive Grammar of the Modern Language, London: Routledge |
| Russian | современный русский литературный язык | Малый академический словарь (МАС) https://rus-academic-dict.slovaronline.com/ |
| Turkish | Turkish / Modern Standard Turkish (ISO 639-3 = tur) | Türk Dil Kurumu |
Additional tasks
Annotate CUs for written data
For the written registers (iw, fw), we currently lack a syntactic unit. Furthermore, CUs as segmentation units were, amongst other reasons, chosen due to their applicability for spoken and written data. Having CUs in all types of texts facilitates cross-mode / cross-register comparisons.
To do this in EXMARaLDA, you first need to create the respective annotation tier. After having opened your file in EXMARaLDA, add a new tier through the menu bar (Tier > Add Tier). Choose the following settings:
- Speaker: dipl [dipl]
- Type: A(nnotation)
- Category: cu
By depending on the diplomatic tokenization, the tier has one timeslot per event on dipl. To annotate a CU, merge all timeslots in the CU tier that overlap the tokens (dipl) belonging to the CU (including sentence-final punctuation). Finally, assign a simple annotation value "cu" to the newly created span.
The CU tier does not explicitly contain any text. By overlapping its respective tokens, the entire text of a CU is already defined and can be searched.
Please do not edit the CU layer of the transcriptions. They are final.
Adapt language annotation
For each dipl token there is a lanuage annotation. When preparing your data, this is automatically set to the language of elicitation. Nevertheless, in some cases you might have to adapt that value. Please use the ISO 639-2 language code. A list of valid codes can be found here.
For cancellations, pauses, emojis and non-verbal material, please delete the language annotation.
Normalization guidelines
The rules are always applied on the normalized tokenization. The diplomatic tokenization remains as is.
The following lists and examples are planned to be extended and updated with more exmaples, especially from Greek, Russian and Turkish.
Notation: Normalization rules are formulated as diplomatic token(s) → normalized token(s). Token boundaries are represented with a slash (/).
| Phenomenon | What to do on norm level? | English example | German example | Russian example | Comments / Rationale / Criticism |
|---|---|---|---|---|---|
| (CU-initial) capitalization | do not correct. Only adapt if a word itself has to be capitalized. Do not capitalize merely because of a CU-initial position | am / i / in / london → am / I / in / London | das / auto / konnte / nicht / mehr / bremsen → das / Auto / konnte / nicht / mehr / bremsen |
Note: Rule of thumb: Capitalize, if the word needs to be capitalized in the orthography of reference. Only introduce capitalization if it is the correct spelling independent of whether it appears in an initial position or not. Also, do not undo CU-initial capitalization if provided by writer.
| Phenomenon | What to do on norm level? | English example | German example | Russian example | Comments / Rationale / Criticism |
|---|---|---|---|---|---|
| orthographic errors or phonetic assimilations / slip of the tongue | normalize orthography | orthographie → orthography | hunt → Hund fümf → fünf | ~ | 1 |
| orthographic errors or phonetic assimilations / slip of the tongue (within vocabulary) | correct to target hypothesis if meaning of corrected form is much more likely AND the normalization implies a change in category | I / was / their → I / was / there | ihr / seit / dort → ihr / seid / dort Umfall → Unfall | ~ | 2 |
| written data: composed forms | refer to above mentioned reference and normalize | inter-national → international caraccident → car / accident | Auto / Unfall → Autounfall |
This is the prototypical case of normalization.
Both corrections are much more likely, since it is very hard to derive any meaning from the uncorrected examples, considering they were meant to be this way. Additionally, since it is 1-1 normalization in terms of words, normalization is not particularly invasive. Last but not least, since the elicitations take place in a more or less closed setting, it is much easier to make a judgement on the likelihood of an expression in a case of potential within-vocabulary errors.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| missing words | do not add them, we do not normalize syntax | you / there / ? → you / there / ? | bin / unterwegs → bin / unterwegs |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| repetitions | keep, normalize orthography | the / the / cAr → the / the / car | ein / ein / Autounfall |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| self-corrections | see repetitions / cancellations | the / hatchback / (eh) / car → the / hatchback / car (filled pause deleted, rest remains) | ein / Typ / ein / Fußgänger / hat / dann remains as is, whereas ein / Fußg/ / ein / Typ → ein / ein / Typ, since Fußg/ was explicitly marked as cancelled by the transcriber |
Note: The proposed procedure for self-corrections is the least theory-driven, thus, avoids making any grammatical assumptions when normalizing. Nevertheless, or therefore, it also might be very controversial. It definitely does not facilitate later syntactic annotation.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| spoken data: cancellations3 | drop the incomplete element | car / acc/ → car | Autounf/ → |
Note: Sometimes it is difficult to tell whether something is a cancellation or not, because the incomplete part might already be a word on its own. In these cases we rely on the transcriber's decision: If something is marked as cancellation in the transcript, we stick to that interpretation. Nevertheless, that should not keep your project from revising transcriptions (given the current state of corpus creation still allows for such revisions).
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| spoken data: phonetic markers | remove and normalize to orthography | a::nd → and | und / da::nn → und / dann |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| reduced forms | if reconstructable normalize orthographically4 | ca → car | nich → nicht wolln → wollen |
Note: reduction has to be out of vocabulary. If not, check with the guidelines on within-vocabulary errors above.
Note: There might be (even in the dictionary) widely accepted variants of standardized writings that are more or less the result of reduction (or other processes). Examples are cross instead of across in English, grade instead of gerade in German. We need to focus on the goal of normalization: To have a text segmentation where orthographic variation is reduced / removed, i. e. where multiple expressions are mapped to one standard representation. Thus, as long as there is no argument that normalizing an item alternates meaning, these reductions should be normalized. We only deal with mappings from one token to one token, i. e. retrieving the originally chosen expression is very easy and we do not lose information. A counterexample are cases of drauf in German. As a pronomial adverb it is often a reduction of darauf and should be normalized as that. Nevertheless, it can also be the separated particle of the particle verb draufgehen (to die, fig.) and normalizing it to darauf would not be appropriate/"correct". When normalizing, we will most likely encounter much more subtle cases of difference in meaning. We need to discuss and document our decisions.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| colloquial forms, dialect | normalize | coz → because rulz → rules cha → you | nix → nichts ick → ich jetze → jetzt itzt → jetzt |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| merged forms | split into normalized items as long as both items are visibly represented in the merged form | wanna → want / to gonna → going / to 5 | kannste → kannst / du 6 |
Note: regarding (1) and (2)
what / cha / gonna / do → what / you / going / to / do
Note: kannst / mir / mal / helfen
remains as is, since there is no overt material for du without assuming a reduction of kannst, i. e. this is a case of missing material, not merge (see above)
| Phenomenon | What to do on norm level? | English example | German example | Russian example | Comment |
|---|---|---|---|---|---|
| merges / clitics | separate and normalize, if possible | isnt → is / n't withe / ball → with / e / ball he's / guilty → he / 's / guilty | binsch → bin / ich |
Note: We normalize a clitic if there is no ambiguity about the standard form. If the standard form cannot be determined unambiguously, the clitic is represented as a clitic, but in a standardized way (see table below for examples).
English clitics
We always separate the clitics, i. e. divide a single diplomatic token in two norm tokens. See the following list of examples:
| Diplomatic | Normalized |
|---|---|
| n't | not |
| 'll | will |
| 's | 's |
| 're | 're |
| isn't or isnt | is / not |
| aren't or arent (or even arnt) | are / not |
| cannot or can't or cant | can / not |
| won't or wont | will / not |
| didn't or didnt | did / not |
| don't or dont | do / not |
| doesn't or doesnt (or even dosnt) | does / not |
| ain't or aint | ai / not |
| couldn't or couldnt | could / not |
| shouldn't or shouldnt | should / not |
| wouldn't or wouldnt | would / not |
| she'll | she / will |
| he's | he / 's |
| you're | you / 're |
| Thomas' / computer | Thomas / ' / computer |
| Anke's / mail or Ankes / mail | Anke / 's / mail |
German clitics
Separate clitics analogous to English clitics, but do not use an apostrophe.
Greek and Russian clitics
Represent them according to the chosen orthographic standard.
Turkish clitics
Concatenated morphological elements can remain a unit, since this is part of the language. If you prefer to separate them anyway, make sure you work consistently.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| lexicalized merged forms | + do not normalize + work with list? + refer to orthography reference? | Rock'n'Roll → Rock'n'Roll | im → im zum → zum beim → beim ins → ins |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| non-standard variation within a paradigm | normalize | $\dots$ | helf / mir → hilf / mir |
Note: Non-standardized but maybe widely established and accepted forms can be understood as alternative spellings. For alternative spellings our rules guide us to choose a standard and always use that to guarantee consistency. Therefore, normalizing to the true standard form is a good way to go. It is also a safe procedure, since we are dealing with single word to single word mappings, i. e. the original diplomatic form is always retrievable.
Special material / cases
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| speaker codes | do not normalize |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| foreign material / proper names in a foreign language | normalize according to agreement | leik → like |
Note: The transcription of foreign material is always phonographic. The normalization sticks to the habit of the respective language. Whereas the phonographic leik (dipl) might be like (en) on the German norm layer, whereas a Russian that says Autowerkstatt in German in a Russian context, the dipl and norm form will be phonographic representations (аутоверкштат).
Also: Remember to adapt the language annotation for these cases.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| Abbreviations | (merge and) normalize according to standard orthography | pekawe → PKW |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| cardinal numbers | normalize according to regulations in orthography of reference |
Note: In the written data, it is enough to correct the spelling of numeral words, there is no need to convert actual numbers to words or vice versa.
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| floating point numbers | normalize as numbers | one / point / three → 1.3 | eins / Komma / drei → 1,3 |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| times and dates | are a composition of elements for which there are normalization rules to be applied individually |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| fractions | normalize/keep as words | one / third | ein / Drittel |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| pauses, noise, turn-holders, laughing, ... | not represented, i. e. delete token |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| filled pause vs. particle, etc. | If you decide to consider certain filled pauses lexical units, decide on a standardized representation and represent that unit always the same way in the normalization layer. If you are currently undecided on the status of such an element and this is actually part of your research, delete that element on the normalization layer. |
| Phenomenon | What to do on norm level? | English example | German example | Russian example | Comment |
|---|---|---|---|---|---|
| interaction/communication with elicitor | not represented | ... | ... | There is a transcription standard for these events. These events will not be normalized. Delete These events on the norm layer. |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| incomprehensible, no hypothesis (unknown material) | not represented, i. e. delete token on norm | (UNK) | (UNK) |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| incomprehensible with hypothesis | hypothesis is represented in a normalized version | (car) → car | (jetze) → jetzt |
| Phenomenon | What to do on norm level? | English example | German example | Russian example |
|---|---|---|---|---|
| punctuation | do not add nor normalize, but separate on both dipl and norm | accident.Then / the → accident / . / Then / the | ,dass → , / dass |
NOTE: This is a phenomenon you may face in written data. Since there is no obligation for authors to stick to pure typing-conventions and use spaces after punctuation, we will treat cases like the above as tokenization errors caused by the pipeline. To remain within a certain frame of complexity we cannot resolve these issues within automatic tokenization. Please perform the separation during normalization on both - dipl and norm. Each element of punctuation should be its own token, unless it is a sequence of punctuation characters without whitespaces in between. In these cases the characters remain a unit (e.g. "..." stays like this on dipl and norm).
| Phenomenon | What to do on norm level? | English example | German example | Russian example | Comment |
|---|---|---|---|---|---|
| multiple representations allowed in orthography of reference | Make a decision, document it and stay consistent. | Albtraum vs. Alptraum | ~ | This also implies, that if a participant uses the alternative form you should normalize to the variant you chose as a standard in the corpus. |
Grammatical deviations
If there is a mismatch in case, gender or any other grammatical property/feature, do not normalize it. This has to remain to be up to investigation. You might, of course, find non-trivial cases between orthographic normalization and an actual grammatical target hypothesis. Document these case and raise a discussion if necessary.
Annotation Step 3: POS and Lemma
Tools involved
- we prepare lemma, pos and feature annotations for you (automatically)
- you will correct these annotations in EXMARaLDA
- you will find the data in the same subfolder of
exb/as during normalization
If you ever face the following error message when opening an EXMARaLDA file:
Tier ... is not stratified. Please choose a method for stratifying the tier:
Choose Stratify by deletion.
Lemmatization
-
binds several occurences within the corpus to a common type
-
facilitates / enables for search with / for lexical items
-
lemma: standardized form which might occur in different realizations / variants
-
lemma usually (but not necessarily!) determined by paradigms, i. e.:
inflected form → prototype = a single inflected form within paradigm or uninflected form = lemma
- lemmatization varies across annotation schemes and languages
- lemmatization is linked to part of speech
Part of Speech (POS)
- we would like to categorize several lemmata to more abstract categories
- factors for determining a category can be:
- syntactic / distributional
- semantic
- morphological
- graphical
- ...
Know the guidelines and document difficult cases
-
part of speech is the baseline for many further annotations
-
we need correct annotations
-
we will measure agreement
-
highly connected to lemmatization, thus underlies the same restrictions and parameters of variation
Rule of thumb in cases of doubt (Lemma & POS)
Always trust the guidelines more than your “grammatical intuition”, but in cases of doubt consult both.
Language-specific POS vs. UD-POS
- language specific: you might have to find new ways / rules for undescribed phenomena (Please document!)
- UD: strictly stick to UD guidelines for your language and please do not decide by what seems more logical to you
POS – Schemes by Language
| English | German | Greek | Russian | Turkish |
|---|---|---|---|---|
| British National Corpus Part of Speech Tagset | STTS 2.0 | Universal POS tags | MyStem Morphology | MULTILIT |
All languages
Universal Dependencies POS-tags, lemmas, and features
- https://universaldependencies.org/
- https://universaldependencies.org/u/feat/
- https://universaldependencies.org/u/pos/
POS – Who does what?
| English | German | Greek | Russian | Turkish |
|---|---|---|---|---|
| correct BNC-POS, lemma, features (?) | correct STTS-POS, lemma, features (?) | correct UD-POS, UD features, lemma | correct MyStem-POS, lemma, features, and UD-POS | correct MULTILIT-POS, lemma, features (?), and UD-POS (?) |
UD-POS by language
| English | German | Greek | Russian | Turkish |
|---|---|---|---|---|
| derivable | derivable | needs manual correction | needs manual correction (?) | derivable (?) |
Remarks
- delete tier norm [CU]
- feel free to move the tiers up and down
- rename pos_1_1 to pos_lang
- look out for errors in the data and report them immediately
General decisions for all languages:
- lemma "F16" is tagged as a proper noun with the respective tag from the specific tagset you are using (e.g. "PROPN" from Universal Postags)
- all kinds of greetings should be treated as interjections and tagged with the respective tag from the specific tagset you are using (e.g. "INTJ" from Universal Postags), unless there is a specific tag for greetings in the language specific tagset you are using
- regarding the lemmatization of informal greetings: you can just copy the word form from the norm/dipl-layer
Language Specific Decisions
Each language has additional transcription and annotation decisions. These are documented in the following sub-sections. We apologize for any parts of documentation that are not available in English until now, these will be translated and included in future releases of the corpus.
Transcription Decisions English
Transcription decisions: English
Spelling lists for CU Layer.
1. Compounds with hyphens
- rear-end/rear-ended > rearend/rearended (if it is a verb, but if it is a noun, e.g. "rear end of the car", insert space)
2. Hesitation markers
- ɑ > ah
- ɛ > eh
- ɹ [syllabic] > er
- oʊ > oh
- ə > uh
- əm/ʌm > um
- em
- oh
- ha
- mm
3. Merged forms
-
couldn't > couldn=t
-
didn't > didn=t
-
doesn't > doesn=t
-
don't > don=t
-
I'd > i=d
-
I'm > i=m
-
it'd > it=d
-
shouldn't > shouldn=t
-
that's > that=s
-
there's > there=s
-
they're > they=re
-
Unclear determiner ["a" versus "the"] > (det) TBD
-
wasn't > wasn=t
-
we'd > we=d
-
what's > what=s
-
who's > who=s
-
you're > you=re
-
guy's ball -> guys, guy's (guy is) running -> guy=s
-
The following are lexicalized forms that appear in the dictionary: gonna, kinda, wanna.
COMMENT: How do we handle ambiguous cases with determiners e.g. with a vs. with the suggestion: with=e
4. Dropped final stops
- dropped final stop for 'and' > an(d)
- dropped final stop for past tense verbs, i.e. 'happened' > happen(ed)
5. Notations
- [coughing]
- [gulping]
- [laughing]
- [pfing] for a sound like "pfff"
- [tongueclicking], including tsking as disapproval, while thinking and just mouth opening with a click
- [throatclearing]
- [whispering]
- [sighing]
- [sniffing]
- [imitating] - when a person imitates a sound of a crash or other sounds related to the story
- [yawning]
6. Other
- basketball
- ɛf > ef (i.e., case number ef sixteen)
- soccer ball
- renault
- volkswagen
- aysap (for a.s.a.p. 'as soon as possible', if pronounced 'ay-sap', not 'ay ess ay pee')
7. Foreign language material
- hello - preevyet (привет)
- Olya (name), not Olia
English Normalization
Individual acronyms and letters are represented with lowercase letters.
- ef > f
- pe:em > pm
- be:em:doubleyou > bmw
- aysap > asap
Number less than twelve are written out, while numbers greater than twelve are represented as numerals.
- ef sixteen > F16 (one token)
- nine | one | one > 911 (one token)
- -_- emoticons to be left as one token
- consecutive punctuation such as "..." are to be left as one token, unless they are already separated on dipl layer.
- twelve > twelve
Foreign language material
- preevyet (hello) > privet
Abbreviations to be written normalized, even if they are in the dictionary
- sec > second
- prob > "probably" or "problem", depending on the context
Capitalizations
- I
- Renault, Volkswagen, Golf
Other
- rear end (if noun), rear-end (if adjective or verb) e.g. "rear-end collision", "rear-ended", "bumped into the rear end"
English POS and Lemma
BNC: Tag List
- Might be less compatible with American English spellings
- Greater number of tags for accuracy; the tags are highly specific, though not all are necessary for our purposes (i.e., four categories for punctuation). Regardless, researchers searching for broader categories in the corpus should be able to do so by filtering the data appropriately.
- Intuitive tag names
- Multiple codes for determiners
Decisions
- Hi/Hello/Hey : ITJ (Interjection)
- F16: NP0 (proper noun)
- I : PNP
- am -> be: VBB
- like: ITJ (interjection)
- okay (ie. 'he is okay'): AJ0
- kind (of): AV0
- e (det): AT0
- same: AJ0
- as: CJS
- (in) front: PRP
- behind: PRP
- Police: NN0
- 911: NP0 (proper noun)
- no (AT0) one (PNI)
- as (PRP) well (AV0)
- "ish" should be removed during lemmatization (i.e. "smallish" --> "small")
Transcription Decisions German
(in German)
Basics
Transcription Program Exmaralda:
After every interval there must be a space!
Tiers
- speaker (named according to Sigle, e.g. DEmo09FD; type: transcription)
- possibly Comment (communication between transcribers; type: description; information about this level disappears later)
Segmentation and accentuation
- segmentation according to communication units (CU) more information here
- rule of thumb: independent sentences represent a CU. Dependent sentences (verb at the end) represent a CU with the respective independent sentence.
- written data files: the subject's punctuation is taken into account. If a dependent sentence is distinguished from the independent part by the placing of a dot, the dependent sentence is considered a CU.
- no accentuation
- no punctuation
Transcription
Basics
- linguistic material that refers to the task such as inquiries from subjects and possibly interruptions by researchers is marked in the following way:
<Q> communication with elicitor </Q>and receives an own event. - strict use of small initial letters
- predominantly orthographic transcription according to German spelling regulations
- BUT: transcribe according to ear in cases that do NOT comply with the general standard of spoken language! Don't leave out or add anything.
- this includes for instance: nich vs. nicht, kein vs. keinen, jetz vs. jetzt, n vs. ein, is vs. ist, ne vs. eine, ma vs. mal, was vs. etwas, brauch vs. braucht, rum vs. herum, ham vs. haben, isch vs. ich
- when the complete ending is omitted (-en and not only Schwa), e.g. gesprung, angefang, dein
- dialectal, sociolectal and ethnolectal variation is put into writing (not extremely precise)
- standard phenomena of spoken language that will NOT be transcribed but will follow German orthography are:
- omission of vowels in final syllable / deletion of Schwa: always written orthographically (sehn = sehen, machn = machen)
- devoicing in final position (e.g. bald not balt)
- word final er (e.g. koffer not koffa)
- word final g as ch (e.g. König not könich)
- ä stays ä (e.g. später not speta)
- sch in connection with sp/st is noted as sp/st
- simplification from pf to f is not noted
- v and f are used according to spelling regulations
- diphthongs are used according to spelling regulations
- individual words: eigentlich, irgendwie
- the metalanguage is English (everything that is not produced by speakers, e.g. non-verbal)
A list of individual choices regarding spelling can be found here
omissions/repetitions/discontinuities
- Don't leave anything out that is spoken. Don't add anything that is not spoken.
- no apostrophes as signs of omission
onomatopoeia/echoisms:
- individual tokens (e.g. gutschi gutschi gutschi)
- unless they are very short - then together (z.B. eieiei)
sequences, repetitions, discontinuities
- transcribe as audibly perceived, don't leave anything out
- mark the discontinuity of words with /
- word internal discontinuity shall be marked such that the discontinued element is bracketed by dollar signs, e.g. dipl: Kinder$gar$ wagen
variations of pronunciation
fusional forms
-
fusional forms (reduction + quick addition) are marked by an equal sign (e.g. is=er, ham=se, so=ne)
-
preposition + article fusions are not additionally marked, but are written together. We do not differentiate between different forms of prep + art. fusions. These include:
- zum, beim, aufm, mitm, fürs, ins, ans etc.
- double consonants: vonner, inner, mitter etc.
- BUT: auser, aufer, zuner etc.
-
a list of spellings can be found here
lenghthening
- orthographic spelling with lenghthening h or doubling of vowels remains, colons (see following examples) are added
- lenghthening in letter combinations: in front of a lenghthening h (e.g. spä::ht), after a dipthong (e.g. polzei::), after a double letter (z.B. see:), after the vocalization of r (e.g. über:)
- longer than normal (0.2-2 Sek.) with a colon (e.g. so la:ng)
- strikingly long (ab 2 Sek.) with :: (e.g. so la::ng)
- doubling of vowel syllables with % (e.g. tschü%üss); can be combined with lenghthening colons (e.g. tschü:%üss); the same goes for diphthongs (e.g. hei%ei)
- drawn-out and long aspirated consonants are also marked with colons (just like the vowels)
compounds
- generally to be written together (e.g. lehrerzimmer)
- compositions of noun+adjective (saumüde), two adjetives (supertoll) or adjective+preposition (übergeil) and particle verbs (leidtun, weggehen) are transcribed as one token
- abbreviations/words with hyphen are not separately marked (e.g. "mathe emesa prüfung" for Mathe-MSA-Prüfung)
- coordination of compounds WITHOUT hyphen (e.g. mittag und abendessen)
- hyphens, provided that correct spelling intends them, remain, e.g. "t-shirt"
- compounds with names as first constituent are spelled with a hyphen, e.g. "rewe-parkplatz"
numbers und dates
- write out in full
- write complex numbers together (e.g. zweikommadrei)
- divide fractions (e.g. zwei drittel)
- divide school marks (e.g. zwei minus)
- divide dates (e.g. elfter dritter)
abbreviations / acronyms
- one word (e.g. "beemwe" for BMW)
- compounds of two abbreviations are not separately marked (e.g. "mercedes eselfka" for Mercedes-S11K)1
proper names/brand names
spelling is kept (e.g. renault)
pauses
- transcribe onto speaker-tier
- pauses between two CUs receive an own event
- pauses within a CU is transcribed within, no own event
- 0.2-1.0 seconds: (-)
- 1.1-3.0 seconds: (--)
- over 3 seconds: enter measured value in brackets, e.g. (5.5)
- word internal pauses are marked the same way, e.g. auf(-)geschlossen (without space before and after the brackets), exception: word internal pause and filled pause (ähm) with spaces, e.g. auf (-) äh geschlossen
extra-linguistic/non-verbal actions
- non-verbal actions such as laughing or coughing are noted on speaker-tier in square brackets, e.g. [laughing]
- simultaneous laughing and speaking, as follows: [[laughing]ball]
- assigning of CU: the same as hesitation markers, non-verbal actions are assigned to the following CU, e.g. "(-) | [laughing] (-) ähm ja das hat mir meine mama schon immer gesagt"
sounds/non-verbal material
- sound imitations are transcribed onto speaker-tier (e.g. "dann hör ick nur so wuh")
- speaker-independent interruptions (e.g. loud car noise, beeping computer) are only transcribed as pause without specification
incomprehensible/hard to understand
- something incomprehensible within a CU is transcribed within the CU in brackets, so no extra interval (UNK) or (UNK, 2.2) über 2 Sekunden
- if it's ambiguous to which CU it belongs, it receives an own event
- assumptions about the content are put into brackets, each lexeme individually, e.g., (vermuteter) (Inhalt)
- assumptions relate to existing lexemes, i.e. if one only hears "ga", one must either mark it as a discontinuity within the brackets, as (ga/) or as (UNK)
Foreign Language Material
- transcribe as heard in German orthography
- EXCEPT with English material, this is kept in English spelling
- AND: words that are listed in the Duden are not considered "Foreign Language Material". They are spelled accordingly (e.g. adieu)
- draw up a list with the spelling of foreign words and their occurrence so they are always spelled the same way, this list can be found here
anonymisation
names of persons
- replace name (first and surname) of speaker with speaker Sigle (e.g. DEmo02FD)
- the Genetive -s is added to the Sigle (e.g. DEmo02FDs)
- first names of absent mentioned people do not have to be anonymised
- surname or first and surname of absent people must be anonymised by speaker Sigle_P (e.g. DEmo02FD_P)
indication of place
- only anonymise if conclusion about place of residence is possible, e.g. when street names are mentioned that could be the address of the speaker
- school: {category}, e.g. Alexander-Puschkin-Schule as {schoolname}schule
- street: {streetname}straße
- if the place is inflected, e.g. plural, the inflection is suffixed: {streetname}straßen
- incomprehensible names of persons without indicating category
particles/signals/interjections
signals of reception
- negation: 'hm'hm, nee, 'ä'ä
- affirmation/signal of reception: 'hmhm
- signal of reception: hm, mhmh
hesitation markers
- fillers: äh, ähm, öh, öhm, (even when they are produced with a glottal stop), hm (even when only m is produced)
interrogation particle (belong to preceding CU)
- always: ne, gell
- sometimes: oder, ja, okay
interjections
A list of all interjections that occur can be found here and is continuously expanded throughout the transcription process.
special characters on the level of transcription
| symbols | meaning |
|---|---|
<Q>...</Q> | questions regarding the task |
| (-) | pause 0.2-1.0 sec. |
| (--) | pause 1.1-3.0 sec. |
| (3.2) | pauses longer than 3 sec. |
| (UNK) | incomprehensible material |
| (UNK, 2.2) | incomprehensible material longer than 2 sec. |
| (assumption) | assumed material |
| [...] | non-verbal action |
| [[...]...] | non-verbal action & verbal material |
| : | conspicuously long vowels/consonants (under 0.2-2 sec.) |
| :: | extraordinarily long vowels/consonants (over 2 sec.) |
| = | reduced forms with quickly following connection |
| / | word discontinuity |
| $...$ | word internal discontinuity |
| % | double syllable |
| {...} | specification of an anonymised place |
| ' | glottal stop |
Interjections
Spelling decisions
This page documents the decisions taken concerning the spelling of specific words and documents the occurences of foreign language material (FM).
Alphabetical list of spelling decisions:
- baby (duden, wenn "bebi/be:bi" produziert wird)
- basecap (wie im duden)
- beemwe
- bissn (wenn nicht bisschen, sondern bissen oder bissn produziert wird, z.B. DEbi02FG_fsD: 22.05)
- cap (wie im duden) ABER käppi
- cops (wie im duden)
- crash (wie im duden)
- einskommafünf liter flasche (1,5l-Flasche)
- fauwe (VW)
- genuch (wenn es so produziert wird)
- ha u (für HU, also die Abkürzung der Humboldt Universität)
- hey (duden, wenn "häi" produziert wird)
- hi (duden, wenn "hai" produziert wird)
- ick (ich auf berlinerisch)
- iks üpsilon straße (für xy straße)
- käppi
- limousine (spricht natürlich limusine)
- nix (wie duden)
- nochmal
- pekawe (oder besser pekawe, weil ein Doppelpunkt eine Längung über 0.2 Sek. anzeigt, die meist nicht vorhanden ist bei pekawe, wenn doch, dann natürlich mit :)
- pekawe fahrer (PKW-Fahrer)
- revue passieren (wie im duden)
- so was
- tschau (empfohlene Schreibweise duden)
- tschüss
- van (Van wie im duden) (auch minivan)
Alphabetical list of foreign language material (with specification of the occurence):
english expressions are transcribed following the english orthografie:
- crashen (DEmo12MD_isD / 00:30, Ebi08MG_isD / 00:44) im online Duden gelistet (eingesehen 15.04.2019, 9:57), Wert auf lang: deu
- bystander (DEmo32FD_isD / 01:24) nicht im online Duden gelistet (eingesehen 15.04.2019, 10:00), Wert auf lang: eng
- dude (DEmo53FD_isD / 00:24) nicht im online Duden nicht gelistet (eingesehen 15.04.2019, 9:59), Wert auf lang: eng
- plep [pleb = dt. Prolo] (DEmo74MD_isD / 00:28) nicht im online Duden gelistet (eingesehen 24.04.2019, 12:32), Wert auf lang: eng
other foreign language material, as perceived:
- dawei (rus)
- vallah (ara)
anderes:
- kränk [von krank mit englischer aussprache] (DEmo71FD_isD / 01:35)
Merged forms
This page documents merged forms that occur in the German RUEG data and how they are trancribed.
Merged prepositions and articles; without extra-marking:
- anner
- aufer
- aufm
- aufn
- auser
- ausm
- beim
- hinterm
- hinters
- im
- inner
- ins
- mitm
- mitn
- übern
- vonnem
- vonner
- vors
- zum
- zur
Lexicalized merged forms; without extra-marking:
- son, sone (für solch, solche) also bei folgendem Substantiv im Plural
All other merged forms are marked with "=":
- auch=n (auch ein)
- bist=e
- dass=es
- d=is (das ist)
- d=is=n (das ist ein)
- gab=s
- geht=s (geht es)
- gib=s
- grad=n
- hab=s
- ha=ich (hab ich)
- hat=ter (hat der / hat er)
- hat=n
- hat=s
- hättest=e
- ich=n
- ich=s
- is=er (ist er)
- is=es (ist es)
- is=n
- kennst=e (kennst du)
- muss=er
- noch=n
- nu=ma (nur mal)
- ob=s
- sa=ma (stark zusammengezogenes sag mal)
- so=m (so einem)
- so=n (so ein)
- so=ne (so eine)
- und=n
- un=an (und dann, komplett ohne Plosiv produziert)
- war=n
- war=s
- weil=et (weil es)
- wie=s
- wird=s (wird es)
- wollt=er (wollte er; so geschrieben, weil nicht entscheidbar ist, ob es wollt er oder wollte er ist)
- zwar=n
German Normalisation
(in German)
Basics
The RUEG-Korpus' general guidelines for normalisaton apply: Step 2: Normalisation
In the following, a few principles will be repeated and language specific decisions included.
- orthographic normalisation
- no normalisation in the syntax
- no grammatical normalisation
- discontinuities and pauses are erased and receive an empty event (on language level the value for discontinuities and pauses is erased -> empty event); EXCEPT word internal discontinuities (dipl: vorbeige$le$ rollt, norm: vobeigerollt)
- repetitions remain
- spoken: non-verbal material, such as [laughing], is not transferred -> empty event
- punctuation marks are not included
normalisation of pronunciation phenomena
- this counts also for the written files - (change 7.10.2019)
reductions of determiners, adjectives and nouns are not normalised with respect to case and gender information*:
| dipl | norm |
|---|---|
| schön guten tag | schön guten Tag |
| mit ein hund | mit ein Hund |
| so ein klein hund | so ein klein Hund |
reductions and slip of the tongues of verbs, nouns etc. not related to case and gender marking are normalised:
| dipl | norm |
|---|---|
| is | ist |
| Umfall | Unfall |
| gesprung | gesprungen |
short forms of indefinite articles are normalised as:
| dipl | norm |
|---|---|
| n | ein, einen |
| nen | ein, einen |
| ne | eine |
| eim, nem | einem |
-
normalise 'nen' as 'ein' in cases of nominative masculine and nominative/accusative neuter, e.g.:
- dipl: "da is nen auto um die ecke gebogen". norm: "da ist ein auto..."
- dipl: "ich hab nen auto gesehen". norm: "ich habe ein auto..." BUT not in: dipl: "nen ne vollbremsung" as norm: "einen eine vollbremsung"
-
so=n either as "so ein" or as "so einen", depending on the context:
- dipl: "so=n typ hat mitm ball...". norm: "so ein Typ hat mitm Ball"
- dipl: "die frau hat so=n hund dabei". norm: "die Frau hat so einen Hund dabei"
According to the Duden and scholarly literature (e.g. Vogel 2006, Schäfer & Sayatz 2014), 'n' and 'nen' can each represent both ('ein', 'einen'). One normalises according to the principle of minimal deviation from the standardly expected form.
hesitation markers / filled pauses
- hesitation markers are all normalised as „äh“, these include äh, ähm, öh, hm etc.
| dipl | norm |
|---|---|
| äh, öh, ähm, hm etc. | äh |
no lexical changes
- when meaning is clearly constant, determine and document a standard, such as:
| dipl | norm |
|---|---|
| aufgrund, auf Grund | aufgrund |
| andren,anderen | anderen |
| bro, brother | brother (lang=eng) |
| Dicker, Digger | Dicker (29.05.2019) |
| etwas, was | etwas |
| grad, grade, gerade | gerade |
| gern, gerne | gerne |
| habe, hab | habe |
| hey, hi, hei (as greeting, not as outcry) | hi |
| langlaufen | entlanglaufen |
| mache , mach (imperative) | mach |
| nichts, nix | nichts |
| noch mal, nochmal | nochmal (28.05.2019) |
| rumspielen | herumspielen |
| rum | herum |
| runterfallen | herunterfallen |
| sodass, so dass (when conjunction) | sodass |
| vorn, vorne | vorne |
- when change of meaning is possible or when context is restricted, leave lexemes as they are, the variations remain:
- daran, dran
- darin, drin, drinnen
- drauf, darauf
- sone (as in "sone autos", so only for plural nouns), solche
- reinfahren, hereinfahren, hineinfahren
- auffahren, rauffahren, drauffahren
- reinpacken, einpacken, hineinpacken
Foreign Language Material (FM) and translingual elements
- FM with German inflection, e.g.:
| dipl | norm | lang |
|---|---|---|
| gecrasht | gecrasht | eng/deu |
- material that is included in the Duden, such as sorry, Van etc. are marked as deu on language level. The Online-Duden serves as a reference, the date of the viewing must be documented (list FM).
numbers...
- until twelve: spelled out
- beginning with 13: numerals
- in the written texts, keep the variation the subject chose
individual choices
| dipl | norm |
|---|---|
| pekawe | PKW |
| ef sechzehn | F16 |
- gender gap
- dipl: Fußgänger innen; norm: Fußgänger_innen
Language Values
| dipl | norm |
|---|---|
| deu | deutsch |
| eng | englisch |
| ara | arabisch |
| tur | türkisch |
| spa | spanisch |
written texts
-
include CU level
-
'dass' as conjunction if spelled 'das' is normalised to 'dass'
-
punctuation marks:
- do not add any, do not correct any, except when missing a space:
dipl norm eingepackt.auf eingepackt / . / auf - several punctuation marks one behind the other without space, e.g. three dots: … leave in an event
dipl norm ... / ... / - if there is a space in between, then also leave it, e.g. . /. / .
dipl norm . . . /. / . / . / -
Emojis
- include Emojis such as :) on norm
-
abbreviations/acronyms
- conventionalised abbreviations are left on norm
- unconventionalised abbreviations or acronyms are spelled out, e.g. dipl: kp norm: kein | Plan
- acronyms that are also "action words" (e.g., lol) are left this way on norm
German POS and Lemma
(partly in German)
Model: STTS 2.0 (Westphal et. al.)
The guidelines can be found here: Westpfahl_Schmidt_Jonietz_Borlinghaus_STTS_2_0_2017.pdf
Decisions POS tag
Here you find some data specific decisions and some cases that are specified in STTTS 2.0 and highlighted here:
- Following Rehbein 2013, we add the tag EMO for emticons and emoji to the STTS 2.0 tagset
- F16 as NE
- one word greetings and terms for saying goodbye as hi, hallo, tschüss are interjections (NGIRR)
- speaker-codes, anonymised streetnames, etc. are proper nouns (NE)
- names that were anonymised by the speaker, e.g., "Frau XX" or "XY Straße" receive the tag XY (non-word)
- if it is not possible to decide on a POS tag, e.g., due to unfinished utterances, the event stays empty
- conventionalised abbreviations (e.g., "d.h.") receive the POS tag ADV (guidelines p.13)
- "also" receives the tag SEDM or ADV depending on the context:
- "also"/SEDM in the pre-prefield, e.g., "also/SEDM ich heiße..."
- "also"/ADV: adverbial connector, e.g. "also/ADV ging ich die Straße entlang", connector signaling a specification (without verb), e.g., "...eine Familie, also/ADV Frau, Mann, Kind" or a correction, e.g., "derweil ist dann ein Auto gekommen äh entgegen also entlanggekommen"
- "wie" in "wie folgt" as KOKOM (see guidelines p.44 for other uses)
- "als"
- "als"/KOUS if it introduces a subordinate clause
- "als"/KOKOM in prototypical cases such as "ich bin größer als du", here also in "ich möchte als Zeuge aussagen"
- if "natürlich" can be replaced by "selbstverständlich" it receives the tag ADV
- interrogative adverbs "wo, wie, worüber, warum" can be used as interrogatives or can serve as relative pronouns. In both cases, they get the POStag PWAV (STTS, S.26). Examples:
- "auf dem Mittelstreifen, wo/PWAV der Unfall passiert ist"
- "ich weiß nicht, wo/PWAV du bist"
- "wo/PWAV bist du"
- "was, welche" can appear
- as interrogative pronouns, also in embedded contexts
- substitutively: "Ich weiß nicht, was/PWS du gemacht hast"
- attributively: "Welche/PWAT Farbe hat der Hut?";
- as interrogative pronouns with a relative use after verbs of dicendi/sentiendi nature
- "Er erzählt, was er gesehen hat"
- as relative pronoun (PRELS) if the antecedent is mentioned previously
- "das Kind, welches/PRELS sich auf der anderen Seite befand"
- as interrogative pronouns, also in embedded contexts
Weitere Beispiele
| token | POS tag |
|---|---|
| /aufgrund /von | /ADV /APPR |
| /aufgrund (des Unfalls) | /APPR |
| /bis /später | /APPR /ADJD |
| /gegenüber /von | /ADV /APPR |
| /gegenüber /dem /Auto | /APPR /ART /NN |
| /nichts /weiter | /PIS /PTKMWL |
| /weder /noch | /KON /KON |
| zwar | ADV |
| ... | $. |
Decisions lemma:
- lemma represents the shortest converging form
- nominalisations stay (Verletzte, Folgendes, Fahrer, etc.). The lemma represents the shortest converging form, so that POS and lemma match (e.g., norm: "das Spielen", pos_lang: NN, lemma: Spielen)
- speaker codes stay as they are
- the lemma of merged forms of articles and prepositions is the preposition: norm:"aufm", lemma:"auf"; norm:"mitm", lemma:"mit"; norm:"zum", lemma:"zu"
- dates are represented by @card@
- cardinal numbers stay on lemma as they are on norm layer, e.g., "zwei", "16"
- reflexive pronouns on lemma are their corresponding personal pronouns (e.g., sich zu er|sie|es)
- ordinal numbers stay as they are on norm layer
- different forms of one lexeme, because related to gender and case marking, are reduced to the shortest converging form (see table below); EXCEPTION: NN denotating persons stay in the same gender form as on norm layer, e.g., "Augenzeugin" and "Augenzeuge"
- "der", "die", "das" are always reduced to "d", no matter if it used as article, relative pronoun or demonstrative pronoun
- forms in plural get the singular form on lemma (e.g., norm: Einkäufe, lemma: Einkauf)
| different forms | lemma |
|---|---|
| all, alle, alles, aller | all |
| andere, anderer, anderes | ander |
| eine, einer, ein | ein |
| der, die, das | d |
| diese, dieser, dieses (atrribuierende Demonstrativpronomen) | diese |
| dieser, dies, dieses (substituierendes Demostrativpronomen) | dies |
| Folgendes, Folgende, Folgender | Folgende |
| jener, jenes, jene | jene |
| mein, meiner, meine, meins | mein |
| weit, weiter, weitere, weiterer, weiteres | weit |
| welche, welcher, welches | welch |
| vordere, vorderer, vorderes (ADJA) | vordere |
| zweit, zweite, zweiter, zweites | zweit |
Transcription Decisions Russian
0. General information
-
no capital letters
-
abbreviations/acronyms are transcribed as full words (e.g. ДТП = дэтэпэ)
-
lower case for all words, even at the beginning of a sentence ==> exceptions: participant code, participant code + _P and symbols like (UNK) etc.
-
the transcription of the participant speech shall generally take place in accordance to the standard orthographic rules of Russian
-
but: if the participant articulates utterances or words, which are not typical neither for the standard Russian nor for the oral vernacular language (повседневный язык) of Russian, transcribe it as it was articulated by the participant
Example from USbi52MR_fsR:
Participant: потому что они два два (-) не видели (-) ==> Standard and vernacular Russian: потому что они друг-друга не видели ==> два два is not typical for the standard or oral vernacular Russian ==> Transcription: потому что они два два (-) не видели (-)
Example:
Participant: мужик играл с футболом ==> standard and vernacular Russian: мужик играл с мячом ==> с футболом in this context is not typical neither for the standard nor for the vernacular Russian ==> Transcription: мужик играл с футболом
-
typical phenomena for standard and vernacular Russian, which shouldn't be transcribed:
-
reduced vokals (if it is not a special dialect of Russian)
Example:
Participant: ана талкает каляску, а мужык играет смячикам ==> Transcription: она толкает коляску, а мужик играет с мячиком
-
so called phonetic words (= words, which are articulated as one word ==> it often concerns prepositions and the following noun)
Example:
Participant: он вышел издому ==> Transcription: он вышел из дому
-
1. Tiers
- two tiers should be used
-
- tier = speaker tier ==> is only used for the transcription of the participant speech; it gets marked with the participant code
-
- tier = comment tier ==> the comment tier is an optional tier and used for communication between transcribers; later (that means: after the transcription) the comment tier will be deleted
-
2. Segmentation
-
NB:
- 1 independent/main clause (главное предложение) = 1 simple sentence (простое предложение)
- 1 independent clause (главное предложение) + 1 or more dependent clauses (придаточное предложение) = complex sentence (сложноподчинённое предложение)
- 1 independent clause (главное предложение) + 1 or more independent clauses (главное предложение) = compound sentence (сложносочинённое предложение)
-
hint: an independent clause can always stand alone; a dependent clause should never stand alone, because without its independent clause the dependent clause wouldn't make sense
-
in addition: a compound sentence can be easily recognized by certain conjunctions, which connect the independent clauses in that type of sentence: these conjunctions are coordinating (соединительный), adversative (противительный) or disjunctive (разделительный) conjunctions (союзы), such as и, но, а, или, либо...либо etc.
-
dependent clauses in complex sentences can be recognized by conjunctions and relativizers like потому что, когда, что, кто, который, чтобы, так как, но и etc.
-
the participant speech gets segmented in communication units (CUs)
-
1 CU correlates with 1 simple sentence or with 1 complex sentence; sentences, which consist of more than 1 independent clause (= compound sentence), are in every case more than 1 CU:
-
Simple sentence
Example from DEbi52FR_isR:
я стала свидетельницей (-) а: (-) столкновение двух машин | ==> 1 CU
-
Complex sentence
Example from DEbi52FR_isR:
виноваты были не машины а: (-) один (-) эм мужчина который (-) ну кот/ ещё более такой (-) молодой | ==> 1 CU
-
Compound sentence
Example from DEbi03FR_isR:
хотела с тобой это поделить | но я была здесь на парковке у реве | ==> 2 CU's
-
-
if a compound sentence includes a VP coordination or an ellipsis, such sentence is to be annotated as one CU:
Example:
она вышла из магазина [subject ellipsis] уронила пакет и [subject ellipsis] пошла дальше | ==> 1 CU
-
discourse marker (ну, ну там, вот, так, как бы, получается, эм, то есть etc.) and the following utterance will be seen as one CU
Example from DEbi03FR_isR:
ну там я предполагаю там ребёнок внутри был | ==> 1 CU
-
discourse markers (ну, ну там, вот, так, как бы, получается, эм, то есть etc.), which specify the precursory utterance, will be seen as one CU, too
Example from DEbi02FR_fsR:
хм их было трое то есть э маленький ребёнок э: женщина и мужчина | ==> 1 CU ("маленький ребёнок э: женщина и мужчина" is a specification of "трое")
-
greetings (привет, здравствуйте, здорово, здрасте etc.) will be defined as an extra CU
Example from DEbi03FR_isR:
привет DEbi03FR_P | слушай я сейчас видела здесь такую ситуацию | ==> 2 CU's
-
question tags such as правда?, или?, правильно?, правильно понял?, не так ли? etc. belong to the previous CU
Example:
ты вася пупкин, правильно | ==> 1 CU
-
in case you are not sure, make less CU's, to facilitate the SUD annotation
-
keep in mind, that punctuation marks are not used at all ==> that means: no full stops, no commas etc.
3. Anonymization
-
replace the name of the participant with the respective code ==> e.g.: DEbi52FR
-
if whole names or surnames of the participant’s friends are mentioned, replace them with the participant code + _P
Example from DEbi52FR_isR:
привет DEbi52FR_P
-
places, that could lead to the identification of the participant, should be replaced as following
Example:
я хожу в Leo-Tolstoi-Schule ==> я хожу в {schoolname}шуле
я живу на улице Шютценштрассе ==> я живу на улице {streetname}штрассе
-
anonymization in Audacity: the name of the participant should be anonymized with the aid of white noise
4. Hesitation markers
-
hesitation markers do not represent an own event ==> they belong to the concerned CU
Example from DEbi52FR_isR:
я когда шла э: на автобусную остановку (-) эм: ==> 1 CU
-
general notation:
- m-hm (confirming) = угу
- ehm = эм or э:м
- hm = хм
- eh/uh = э or э:
- ɑha = ага
- ah = а:
5. Long vocals and consonants
- vocals pronounced longer than normal (under 2 seconds) are marked with a colon ==> e.g.: ну: да
- vocals that are pronounced extremely long (2 seconds and longer) are marked with two colons ==> e.g.: ну:: да
- long pronunciation is also possible for consonants ==> e.g.: тс: тише
- doubling of vocal syllables are marked with % ==> e.g.: ты точно сделал? да%а
6. Pauses
- are transcribed on speaker tier
- a pause between two CU´s is marked as an own event ==> the pause gets two boundaries
- pauses in a CU get transcribed within the concerned CU ==> they do not represent an own event
- word internal pauses are marked in the words and without a space between the parts of the concerned word ==> e.g.: с э(-)тим мячиком ==> exception: pauses with эм in a word ==> e.g.: они на (-) эм крыли стол
- general notation:
- 0.2-1 second ==> (-)
- 1-3 seconds ==> (--)
- longer than 3 seconds ==> time should be measured and noted in brackets ==> e.g.: (3.1), (5.5)
- background noise like traffic noise, phone ringing or computer noise are noted as pauses
7. Merged forms
-
merged forms are transcribed as they are articulated, but with an equal sign linking the merged elements
Example from USbi52MR_fsR:
с одной стороны (-) дороги (-), э, шли муж=женой
8. Reduced syllables
-
general rule: reduced syllables should be transcribed in its full length, even if it was differently articulated
Example:
participant: она токо что шла на улице ==> transcription: она только что шла на улице
-
exception: if a word can be found with its reduced syllables in a dictionary (e.g. MAC ==> Link ) and the participant articulated the word in its reduced form, then the reduced form of the word should be preferred for transcription
Example:
participant: здрасте ==> transcription: здрасте Link zum MAC
-
use / to mark unfinished words
Example from DEbi52FR_isR:
сегодня (-) э когда я шла на авто/ астобв/ (-) а (-) автобусную остановку
9. Numerals and dates
-
numbers should be transcribed by words, since Russian numbers are often inclined or morphed
Example:
я вижу двух* женщин*
-
dates should be transcribed by words, too
Example:
я родился двадцать первого* января тысяча девятьсот девяносто пятого года*
10. Spelling for russified lexicals
-
general rule: foreign words should be transcribed into Russian as they are articulated
-
in addition: for this case exists a special list, where you can search for words like that or add new words Link ==> important: all transcribers have to transcribe these words into Russian eaqually
- Autowerkstatt = аутоверкштат
- Truck = трак
- Ort = орт
- REWE = реве
- Renault = рено
- also = алзо
- OK_ = окe
- WhatsApp = воцап
- {schoolname}schule = {schoolname}шуле
- {streetname}straße = {streetname}штрассе
-
table for russified lexicals
German/English word Russified word Code File Second accident аксидент USbi06FR fsR 6,94 accidentally аксидальтально USbi07MR fsR 15,1 Aldi алди DEbi64MR fsR 8 also алзо DEbi56FR fsR 36,85 Autowerkstatt аутоверкштат DEbi51FR fsR 93,75 bag бег USbi59FR isR 164,23 Ball (mit dem) болом DEbi12FR fsR 16,9 Ball бол DEbi12FR fsR 19 in the back ин зе бэк USbi74MR isR 53,92 ciao чао DEbi04MR isR 29,4 case кэйз USbi86FR fsR 4,62 crash крэш DEbi12FR fsR 47,78 crashed крэшовали DEbi15MR isR 37,56 hey хей USbi73FR isR 0,64 like лайк USbi86Fr fsR 73,13 message месседж USbi16FR isR 8,23 911/nine one one найн уон уон USbi59FR isR 83,64 911/nine eleven найн элэвэн USbi73FR fsR 59,29 OK окей USbi05FR isR 64,7 Ort орт DEbi53FR fsR 23,19 parking lot паркинг лот USbi74MR isR 7,48 Renault рено DEbi10MR isR 31,71 representative рэпрезэнтэтиф USbi74MR fsR 3,85 Rewe реве DEbi03FR isR 13,9 Schützenstraße Шютценштрассе DEbi04MR fsR 5,14 spilled/spilt сплыть USbi58FR fsR 36,41 stopped стопт USbi58FR fsR 25,22 stroller строллер USbi79MR isR 51,8 Truck трак USbi52MR fsR 77,39 turn торн USbi74MR isR 36,32 Vans вэнс USbi59FR isR 12,59 WhatsApp воцап USbi52MR isR -
if already exists a conventionalized spelling in Russian for a foreign word, the conventionalized spelling should be preferred
Example:
Messenger = мессенджер
11. Notations of non-verbal material, uninterpretable material and background noise
-
non-verbal events like laughing or coughing are noted in square brackets on speaker tier and always belong to the concerned CU
-
general notation
- [throatclearing]
- [coughing]
- [laughing]
- [pfing] ==> for a sound like „pff“
- [sighing]
- [sniffing]
- [tongueclicking] ==> including tsking as disapproval, while thinking and just mouth opening with a click
- [yawning]
- [gulping]
- [whispering]
- [breathing]
-
if the participant speaks and makes a non-verbal event at the same time, it is noted as:
- [[coughing]word]
- [[laughing]word]
- [[sighing]word]
- [[tisking]word]
- [[yawning]word]
- [[gulping]word]
- [[whispering]word]
Example from DEbi52FR_isR:
ты [[laughing]знаешь] что сегодня случилось
-
uninterpretable material is to be marked as (UNK) on speaker-tier
-
if it is not clear, to which CU the UNK belongs, make an own event ==> that means: write the UNK between two boundaries
-
if the UNK is longer than two seconds, measure the time and write the time together with UNK in one bracket ==> e.g.: (UNK, 2.1)
-
assumed content is noted in brackets, each token has to be separated ==> e.g.: (assumed) (content)
-
background noise such as traffic noise, phone ringing or Computer noise should be noted as pauses
12. Table of symbols
| Symbol | Meaning |
|---|---|
<Q> speech </Q> ==> e.g.: <Q> можно я ещё раз </Q> | for questions to the procedure on the part of the participant or for verbal interventions on the part of the elicitor |
| (-) | for pauses 0.2-1 second |
| (--) | for pauses 1-3 seconds |
| (time) ==> e.g.: (3.1) | for pauses longer than 3 seconds |
| (UNK) | for uninterpretable material |
| (UNK, time) ==> e.g.: (UNK, 2.1) | for uninterpretable material longer than 2 seconds |
| (assumed word) | for assumed material |
| [non-verbal action] ==> e.g.: [laughing] | for non-verbal material |
| [[non-verbal action]word] ==> e.g.: [[laughing]знаешь] | for a non-verbal & verbal event |
| : | for unusually long vocal or consonant (under 2 seconds) |
| :: | for unusually long vocal or consonant (longer than 2 seconds) |
| = | for merged words |
| / | for interruption of a word |
| % | for doubled syllables |
| {...} ==> e.g.: {schoolname}шуле | for anonymised places |
Russian Normalization
0. General information
-
the conversion of the participant speech 1 into a correct orthographic form 2, which correlates with the applicable linguistic norm/with the linguistic standards of the respective language (in this case of the Russian language), is called normalization
-
during the normalization of the participant speech morphosyntactic (grammatical) mistakes don´t get respected /don´t get changed into its grammatically correct forms
Example:
Participant: | Я калаской видел | ==> Normalization: | Я коляской видел | 3
-
the normalization is manually carried out in the application program EXMARaLDA
1. Structure of normalization in EXMARaLDA
- EXMARaLDA on normalization level is structured in the follwoing layers:
- dipl-[dipl]-layer
- norm-[norm]-layer
- dipl-[language]-layer
- dipl-[CU]-layer 4
| Layer | Function |
|---|---|
| dipl-[dipl] | shows the original speech of the participant, which never gets corrected - neither grammatically nor orthographically |
| norm-[norm] | here the speech of the participant should be manually normalized (orthographical - not grammatical - corrected) |
| dipl-[language] | shows, to which language the concerned word or emoji belongs 5 |
| dipl-[CU] | here the speech of the participant is segmented into communication units (which is one of the results from the transcription); in case of written files the person, who wants to normalize the file, has to add at first the dipl-[CU]-layer (because it is absent) 6 and then he has to segmente the participant speech in CUs by himself. |
2. The subjects of normalization are ...
- ... files from DEbi---R; USbi---R and RUmo---R with the following symbols at the end:
- _fsR (formal spoken Russian)
- _fwR (formal written Russian)
- _isR (informal spoken Russian)
- _iwR (informal written Russian)
3. Steps of procedure
-
- step: Push/Pull/Fetch in GitHub
-
- step: Open EXMARaLDA Partitur-Editor
-
- step: File ==> Open ==> rueg repository ==> GitHub ==> rueg-corpus ==> exb ==> P3 ==> 1, 2, 3 …
-
- step: verify (in case of the spoken files), if the CUs on dipl-[CU]-layer correlate with the CU-guidelines - if not, please correct it; in case of the written files you have to add an extra CU-layer and then to segment the speech of the participant into CUs according to the CU-guidelines
-
- step: verify, if every single word correlates with its right language on the dipl[language]-layer - if not, please correct it
-
- step: normalization according to the orthographical rules of the Малый академический словарь MAC ==> translate the speech of the participant from the dipl-[dipl]-layer in its orthographically correct form on norm-[norm]-layer and delete all phenomena, which are not necessary for the following annotation levels (lemmatization, POS-taggin etc.) ==> which phenomena this in practice concerns, can be taken from the table in 4. Normalization guidelines and problems
-
- step: Save your results
-
- step: go to GitHub ==> submit your file ==> push/pull/fetch
4. Normalization guidelines and problems
| Phenomenon/Problem | What to do on norm-[norm]-layer | Example dipl-[dipl]-layer | result on norm-[norm]-layer |
|---|---|---|---|
| pauses | delete them 7 | привет (-) ты не (--) ты не поверишь что случилось | привет ты не ты не поверишь что случилось |
| hesitation markers | delete them 8 | там короче эм шла женщина с коляской и э | там короче шла женщина с коляской и |
| phonetic markers | delete them 9 | мальчик играл с мячиком и:: и потом мячик покатился на дорогу | мальчик играл с мячиком и и потом мячик покатился на дорогу |
| emojis | they don´t get removed and receive an own event | / :-P привет / я / сегодня / увидел / аварию :-( / | / :-P / привет/ я / сегодня / увидел / аварию / :-( / |
| punctuation marks (in general) | they don´t get removed and receive an own event 10 | / мячик / покатился / на / дорогу . / потом / собака / начала / лаять . / | мячик / покатился / на / дорогу /. / потом / собака / начала / лаять / . / |
| punctuation marks (many in immediate succession without spaces between them) | keep them in one event | /это / просто / был / кошмар / !!!!! | /это / просто / был / кошмар / !!!!! / |
| punctuation marks (many in immediate succession with spaces between them) | every punctuation mark receives an own event | /это / просто / был / кошмар / ! ! ! ! ! | /это / просто / был / кошмар / ! / ! / ! / ! / ! / |
| merges / clitics 11 | separate and normalize, if possible | муж=женой | муж с женой |
| repetitions | they don´t get removed | / потом / мяч / покатился /на /на/ дорогу / | / потом / мяч / покатился /на / на / дорогу / |
| self-correction in whole words | they don´t get removed and each of them receives an own event | / парень / играл / с/ в /мячик / | / парень / играл / с / в /мячик / |
| unknown material | delete it 12 | UNK | |
| interaction/communication with the elicitor | delete it 13 | <Q> можно я ещё раз </Q> | |
| interrupted speech | delete it 14 | пошёл чтобы пс/ посмотреть | пошёл чтобы посмотреть |
| non-verbal material | delete it 15 | первая машина [tongueclicking] тормозила | первая машина тормозила |
| foreign material | normalize according to agreement and adapt the language from which the word originally comes | ||
| capitalization (in written data ==> iw, fw) | do not correct it at the beginning of a new sentence, but correct it in the middle of a sentence, if it doesn´t conform to the russian orthographic rules | / . / В / семье / был / Муж / , / Жена / и / их / ребёнок / . / | / . / В / семье / был / муж / , / жена / и / их / ребёнок / . / |
| Abbreviations | (merge and) normalize according to standard orthography | 100 км/ч | сто / км/ч |
5. Language values
Each token on dipl-[dipl]-layer has to be marked with an abbreviation, to which language it belongs (language value). In general, this gets conducted automatically, but in some cases you have to change the language value - for example in case of foreign words in the participant´s speech on dipl-[dipl]-layer. If this situation/problem occures, please change the language value (abbreviation). In case, that you don´t know the abbreviation of the respective language, use the ISO 639-2 language code. A list of valid codes can be found here.
| Language | language value on dipl-[language]-layer |
|---|---|
| Russian | rus |
| German | ger |
| English | eng |
6. Additional examples
Common short or colloquial forms that are acceptable according to Малый академический словарь or other academic dictionaries shown on https://rus-academic-dict.slovaronline.com:
| normalized | short or colloquial form |
|---|---|
| этот etc. | тот, того, та, той, то, те, тех |
| здравствуйте | здрасте |
| сейчас/час | щас |
| привет | здарова/здорова |
Common short or colloquial forms that are not acceptable according to Малый академический словарь:
| normalized | short or colloquial form |
|---|---|
| только | тока |
7. Comments
1 The original speech of the participant, which never gets changed (neither in process of normalization nor in process of lemmatization or POS-tagging), is located on the dipl-[dipl]-layer in EXMARaLDA.
2 The orthographically corrected speech of the participant is located on the norm-[norm]-layer in EXMARaLDA. In the most cases, on this layer the events (gaps) are already filled in, but the orthographic accuracy of the words should be checked manually each time.
3 This CU gets translated into its orthographically correct form (калаской ==> коляской). In contrast to this, the grammatical (morphological and syntactic) incorrectness of the CU (the correct government of the verb видеть is видеть кого/что? (Acc.) ==> Я видел коляску** and the more correct word order in this case would be Я вижу калаской) doesn´t get respected or changed at all.
4 In case of written files (_fwR, _iwR) a dipl-[CU]-layer has to be added (in case of spoken files the dipl-[CU]-layer already exists) and the speech of the participant from the dipl-[dipl]-layer has to be segmented in CUs on the added dipl-[CU]-layer.
5 Keep in mind, that in case of foreign words or emojis (f.e. ХД), these words or emojis get transformed into the russian alphabet, but they still stay foreign words (even if they are written in Russian). Therefore, foreign words have to be marked on dipl-[language]-layer with the concerned abbreviation (usually ger or eng) from which language they originally came.
6 You can add a new layer in EXMARaLDA through the menu bar (Tier ==> Add Tier). then, choose the following settings:
- Speaker: dipl [dipl]
- Type: A(nnotation)
- Category: CU
By depending on the diplomatic tokenization, the tier has one timeslot per event on dipl-[dipl]-layer. To annotate a CU, merge all timeslots on the added dipl-[CU]-layer that overlap the tokens on dipl-[dipl]-layer belonging to the CU (including sentence-final punctuation).Finally, assign a simple annotation value "CU" to the newly created span and everything is ready.
The CU tier does not explicitly contain any text. By overlapping its respective tokens, the entire text of a CU is already defined and can be searched.
7 If you delete pauses on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer.
8 If you delete hesitation markers on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer.
9 If you delete phonetic markers on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer.
10 General rule: We do not add and correct any punctuation marks. Only in case, when the punctuation mark sticks to a word, then we have to correct it on norm-[norm]-layer.
11 Clitics are synsemantic/function words (= words without an own semantic meaning [==> therefore, they have a grammatic meaning]), which phonologically "fuse" into their immediate "neighbour" words (which are in most of the cases nouns). That means, that clitics (which are in most of the cases prepositions) and their immediate "neighbour words" (nouns) get articulated as one (phonological) word. Depending on their position (behind or in front of their nouns to which they belong), clitics can be classified in proclitics (if the clitic stands in front of its noun to which it belongs) and in enclitics (if the clitic stands behind its noun to which it belongs).
Example:
работать из (=clitic) дому (=noun) ==> articulation: издому, врач на (=clitic) дом (=noun) ==> articulation: надом
12 If you delete unknown material on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer
13 If you delete the interaction/communication with the elicitor on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer
14 If you delete interrupted speech on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer
15 If you delete non-verbal material on norm-[norm]-layer, then you also have to delete additionally the concerned events (gaps) on dipl-[language]-layer
6. Useful links
- for normalization of the participant speech according to the orthographical rules of Russian on norm[norm]-layer use the Малый академический словарь MAC or Викисловарь
Russian POS and Lemma
0. General information
Lemmatization
- the term lemma may be defined as the base form of a word
- the base form of a word is the form, you can usually find in a dictionary
- for verbs the base form correlates with the infinitive, for nouns with the nominative, and for adjectives with the nominative in its masculine form
- the conversion of a word into its base form is called lemmatization
- the lemmatization is carried out semi-automatically in the application program EXMARaLDA using two POS- and lemma-taggers U-POS and MyStem, however the accuracy of the taggers should be checked manually each time
- the lemmas or base forms of the words can be found in MyStem on the norm[mystem_lex] and in U-POS on the norm[lemma] layer
POS-Tagging
- the term tagging means that each word of the participant is attributed with its part of speech (POS)
- the tagging is carried out in the application program EXMARaLDA by semi-automatic U-POS and MyStem taggers, but the accuracy of the taggers should be checked manually each time
- there are two taggers in EXMARaLDA, which assume the task of POS-tagging - U-POS and MyStem
- keep in mind, that these two tagging-softwares are similar to each other, but not absolutely identical 1
1. Structure of POS-Tagging in EXMARaLDA
U-POS-Layers
- to the U-POS-software belong the layers from norm[Animacy] to norm[voice] as well as the norm[lemma] and the norm[pos] layer
- each layer in U-POS (and MyStem) correlates with a grammatical category
- the meaning of each grammatical category in U-POS gets explained in the following table:
| Layer | Grammatical category | Grammeme | Part of speech |
|---|---|---|---|
| norm[Animacy] | Одушевлённость | Одушевлённость (Anim); Неодушевлённость (Inan) | concerns only nouns |
| norm[Aspect] | Вид | Cовершенный вид [что сделать?] (Perf); Несовершенный вид [что делать?] (Imp) | concerns only verbs |
| norm[Case] | Падеж | им.п. (Nom); род.п. (Gen); дат.п. (Dat); вин.п. (Acc); твор.п. (Ins); предл.п. (Loc); зват.п. (Voc) | concerns all nominal categories of POS |
| norm[Degree] | Степень сравнения | положительная (Pos); сравнительная (Cmp); превосходная (Sup) | concerns adjectives and adverbs |
| norm[Foreign] | иностранное слово | (Yes) | concerns all words, which do not belong to the Russian language |
| norm[Gender] | Род | муж.р. (Masc); жен.р. (Fem); сред.р. (Neut) | concerns only nouns, adjectives and pronouns |
| norm[Mood] | Наклонение | изъяв.н. (Ind); услов.н. (Cnd); повел.н. (Imp) | concerns only verbs |
| norm[Number] | Число | Единственное (Sing); Множественное (Plur) | concerns nouns, adjectives, personal pronouns and verbs |
| norm[Person] | Лицо | Первое лицо (1); Второе лицо (2); Третье лицо (3) | concerns personal pronouns and verbs |
| norm[Tense] | Время | Настоящее (Pres); Прошедшее (Past); Будущее (Fut) | concerns verbs and participles |
| norm[VerbForm] | Форма глагола | Неопределённая форма глагола (Inf); Финитная форма глагола (Fin); Причастие (Part); Деепричастие/Герундий (conv) | concerns verbs |
| norm[voice] | Залог | Действительный (Act); middle voice (Mid); Страдательный (Pas) | concerns verbs and participles |
| norm [lemma] | Base form of a word (Начальная форма слова) | ------ | concerns all parts of speech |
| norm[pos] | POS-Determination of the given word according to UPOS principles | существительное (NOUN); глагол (VERB); прилагательное (ADJ); determiner (DET) [abandon in all cases] ... | concerns all parts of speech |
| norm[Reflex] | Real reflexive verbs (настоящие возвратные глаголы) 2 | (Yes) | concers verbs and participles |
MyStem-Layers
- to the MyStem-tagger belong the norm[mystem_gr] and the norm[mystem_lex] layers
- each layer in MyStem (and U-POS) correlates with a grammatical category
- the meaning of each grammatical category in MyStem can be explained as in the following table:
| Layer | Grammatical category | Grammeme | Part of speech |
|---|---|---|---|
| norm[mystem_gr] | POS-Determination of the given word according to MyStem principles | Every redundant grammeme on this layer gets deleted, except the first grammeme and - if they appear - the grammeme of transitivity (tran/intr) 3 and parenthesis (parenth) | concerns all parts of speech |
| norm[mystem_lex] | Base form of a word | should conform with the base form in U-POS | concerns all parts of speech |
2. The subjects of lemmatization and POS-Tagging are ...
- ... files from DEbi---R; USbi---R and RUmo---R with following symbols at the end:
- _fsR (formal spoken Russian)
- _fwR (formal written Russian)
- _isR (informal spoken Russian)
- _iwR (informal written Russian)
3. Steps of procedure
- 1. step: Push/Pull/Fetch in GitHub
- 2. step: Open EXMARaLDA Partitur-Editor
- 3. step: File ==> Open ==> rueg repository ==> GitHub (or SmartGit) ==> rueg-corpus ==> exb ==> P3 ==> 1, 2, 3 …
- 4. step: Verify if the CUs in every file correlate with the CU-guidelines - if not, please correct it
- 5. step: Verify if every word correlates with its right language on the dipl[language]-layer - if not, please correct it
- 6. step: POS-Tagging ==> verify the accuracy of the POS-Tagging-softwares (U-POS and MyStem)
- 7. step: Delete all features from the norm[mystem_gr]-layer except the first one and - if available - the features of transitivity, parenthesis and other features which are not redundant with U-POS features
- 8. step: Save your results
- 9. step: Go to GitHub (SmartGit) ==> submit your file ==> push/pull/fetch -> commit
4. Tagging-Guidelines and problems
| Phenomenon/Problem | Solution | Example | |
|---|---|---|---|
| participant code | dipl[language]: rus; norm[Foreign]: Yes; norm[mystem_gr]: S, persn; norm[mystem_lex]: USbi05FR; norm[lemma]: USbi05FR; norm[pos]: PROPN; all other grammemes on UPOS-layers get deleted | здравствуйте меня зовут USbi05FR | |
| emojis | dipl[language]: rus; norm[pos]: SYM; all other grammemes on UPOS-layers get deleted | ----- | |
| foreign words, e.g. english words: examine each grammatically e.g. анд | dipl[language]: eng; norm [Foreign]: Yes; norm[mystem_gr]: CONJ; norm[pos]: CCONJ; norm[mystem_lex]:анд; norm[lemma]:анд | and = анд | |
| items, e.g. English items: examine each grammatically e.g. а(н) | dipl[language]: eng; norm [Foreign]: Yes; norm[mystem_gr]: ANUM; norm[mystem_lex]:а(н); norm[lemma]:а(н); norm[pos]: DET [abandon in all cases] | a(n) = а(н) | |
| слова с буквой ё | ё пишется на всех уровнях, кроме на уровне dipl ==> на уровне dipl ничего не изменяется ==> norm[norm]: …ё…; norm[lemma]: …ё…; norm[mystem_lex]: …ё… | ----- | |
| ага | norm[mystem_gr]: PART; norm[mystem_lex]: ага; norm[lemma]: ага; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ----- | |
| блин | norm[mystem_gr]: INTJ; norm[mystem_lex]: блин; norm[lemma]: блин; norm[pos]: INTJ; all other grammemes on UPOS-layers get deleted | ну блин | |
| быстро | norm[Degree] Pos 4; norm[mystem_gr]: ADV; norm[mystem_lex]: быстро; norm[lemma]: быстро; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | эта машина очень быстро ехала | |
| быть | norm[Aspect]: Imp; norm[Gender]: Fem, norm[Mood]: Ind; norm[Number]: Sing; norm[Tense]: Past; norm[VerbForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V,intr; norm[mystem_lex]: быть; norm[lemma]: быть; norm[pos]: AUX 5 | она была уверена | |
| быть | norm[Aspect]: Imp; norm[Gender]: Fem; norm[Mood]: Ind; norm[Number]: Sing; norm[Tense]: Past; norm[VerbForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V,intr; norm[mystem_lex]: быть; norm[lemma]: быть; norm[pos]: VERB 6 | там была собака | |
| весь | norm[Case]: Gen; norm[Gender]: Fem; norm[Number]: Sing; norm[mystem_gr]: APRO 7; norm[mystem_lex]: весь; norm[lemma]: весь; norm[pos]: PRON | от всей души; что скажешь к всему этому | |
| вообще | norm[mystem_gr]: ADV,parenth; norm[mystem_lex]: вообще; norm[lemma]: вообще; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | ну вообще там была ещё одна машина | |
| вот in function to replace something | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: вот; norm[lemma]: вот; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | вот он идёт | |
| вот in function of a modal particle | norm[mystem_gr]: PART; norm[mystem_lex]: вот; norm[lemma]: вот; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | вот а потом мальчик побежал за мячом | |
| врезаться | norm[Aspect]: Perf; norm[Gender]: Fem; norm[Mood]:Ind; norm[Number]: Sing; norm[Tense]: Past; nomr[VerForm]: Fin; norm[Voice]: Mid; norm[mystem_gr]: V, intr; norm[mystem_lex]: врезаться; norm[lemma]: врезаться; norm[pos]: VERB; norm[Reflex]: Yes; all other grammemes on UPOS-layers get deleted | одна машина врезалась в другую | |
| вроде | norm[mystem_gr]: PART; norm[mystem_lex]: вроде; norm[lemma]: вроде; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | вроде никто не пострадал | |
| всё (ещё, равно) | norm[Case]: Nom; norm[Gender]: Neut; norm[Number]: Sing; norm[mystem_gr]: APRO; norm[mystem_lex]: всё; norm[lemma]: всё; norm[pos]: PRON | это всё; всё равно; всё ещё | |
| всё-таки | norm[mystem_gr]: PART; norm[mystem_lex]: всё-таки; norm[lemma]: всё-таки; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | он всё-таки поступил по-своему | |
| всё-таки after conjuctions и, а, но | norm[mystem_gr]: CONJ; norm[mystem_lex]: всё-таки; norm[lemma]: всё-таки; norm[pos]: SCONJ; all other grammemes on UPOS-layers get deleted | как ни крути, а всё-таки придётся решить эту проблему | |
| да | norm[mystem_gr]: PART, parenth; norm[mystem_lex]: да; norm[lemma]: да; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | да так всё произошло | |
| давай | norm[Aspect]: Imp; norm[Mood]:Imp; norm[Number]: Sing; norm[Person]: 2; nomr[VerForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V,tran; norm[mystem_lex]: давать; norm[lemma]: давать; norm[pos]: VERB; all other grammemes on UPOS-layers get deleted | давай | |
| два | norm[Case]: Nom; norm[Gender]: Fem; norm[mystem_gr]: NUM 8; norm[mystem_lex]: два; norm[lemma]: два; norm[pos]: NUM | стукнулись две машины | |
| должен, должна, должно, должны | norm[Gender]: Masc; norm[Number]: Sing; norm[Variant]: Short; norm[mystem_gr]: A, praed; norm [mystem_lex]: должен; norm[lemma]: должен; norm[pos]: ADJ; all other grammemes on UPOS-layers get deleted | он должен был позвонить в полицию, но в конце не звонил | |
| другой | norm[Case]: Acc; norm[Gender]: Fem; norm[Number]: Sing; norm[mystem_gr]: APRO 9; norm[mystem_lex]: другой; norm[lemma]: другой; norm[pos]: ADJ | одна машина врезалась в другую | |
| ДТП (дорожно-транспортное происшествие) | norm[Animacy]: Inan; norm[Case]: Gen; norm[Gender]: Neut (because of происшествие); norm[Number]: Sing; norm[mystem_gr]: S,abbr; norm[mystem_lex]: ДТП; norm[lemma]: ДТП; norm[pos]: PROPN | я стал свиделем ДТП | |
| его, её, их as possessive pronouns | norm[case]: Gen; norm[Gender]: Fem; norm[number]: Sing; norm[Person]:3; norm[mystem_gr]: SPRO; norm[mystem_lex]: она; norm[lemma]: она; norm[pos]: PRON | он уронил её пакет | |
| ехавший | norm[Aspect]: Imp; norm[Case]: Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[Tense]: Past; norm[VerbForm]: Part; norm[Voice]: Act; norm[mystem_gr]: V, intr; norm[mytem_lex]: ехать; norm[pos]: VERB; all other grammems on UPOS-laysers get delated | второй водитель ехавший сзади не успел притормозить | |
| ещё | norm[mystem_gr]: ADV; norm[mystem_lex]: ещё; norm[lemma]: ещё; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | там ещё стояла женщина рядом с машиной | |
| женат | norm[Gender]: Masc; norm[Number]: Sing; norm[Variant]: Short; norm[mystem_gr]: A, praed; norm[mystem_lex]: женатый; norm[lemma]: женатый; norm[pos]: ADJ; all other grammemes on UPOS-layers get deleted | он видимо женат | |
| заезжая | norm[Aspect]:Imp; norm[Tense]:Pres; norm[VerbForm]:Conv; norm [Voice]: Act; norm[mystem_gr]:V,intr,ger; norm[mystem_lex]: заезжать; norm[lemma]:заезжать; norm[pos]:VERB; all other grammemes on UPOS-layers get deleted | одновременно заезжая пара машин | |
| здравствуйте, пока, привет | norm[mystem_gr]: INTJ; norm[mystem_lex]: здравствуйте; norm[lemma]: здравствуйте; norm[pos]: INTJ; all other grammemes on UPOS-layers get deleted | здравствуйте я звоню по поводу | |
| здрасте, приветик | norm[mystem_gr]: INTJ, inform; norm[mystem_lex]: здрасте; norm[lemma]: здрасте; norm[pos]: INTJ; all other grammemes on UPOS-layers get deleted | здрасте я звоню по поводу | |
| значит as вводное слово | norm[Aspect]: Imp; norm[Mood]: Ind; norm[Number]: Sing; norm[Person]: 3; norm[Tense]: Pres; norm[VerbForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V, parenth, tran; norm[mystem_lex]: значить; norm[lemma]: значить; norm[pos]: VERB ; all other grammemes on UPOS-layers get deleted | значит он уронил всё и пошёл | |
| играть | norm[Aspect]: Imp; norm[Mood]: Ind; norm[Number]: Sing; norm[Person]: 3; norm[Tense]: Past; norm[VerbForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V, tran 10; norm[mystem_lex]: играть; norm[lemma]: играть; norm[pos]: VERB | мальчик играл с мячом | |
| как at the beginning of dependent/subordinate clause | norm[mystem_gr]: CONJ; norm[mystem_lex]: как; norm[lemma]: как; norm[pos]: SCONJ; all other grammemes on UPOS-layers get deleted | он не знает как это делается | |
| как in case of comparison or emphasizing | norm[mystem_gr]: PART; norm[mystem_lex]: как; norm[lemma]: как; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | водитель тупой как пробка | |
| как at the beginning of direct questions or at the beginning of indirect questions in suboridinate clauses | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: как; norm[lemma]: как; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | как у тебя дела; подскажите как пройти к библиотеке | |
| как in function of a subordinate conjunction without a comparison meaning, but in form of an adverb | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: как; norm[lemma]: как; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | мальчик показал как пройти к дому; я не знаю как это сделать | |
| кажется as вводное слово | norm[Aspect]: Imp; norm[Mood]: Ind; norm[Number]: Sing; norm[Person]: 3; norm[Tense]: Pres; norm[VerbForm]: Fin; norm[Voice]: Act; norm[mystem_gr]: V, parenth, tran; norm[mystem_lex]: казаться; norm[lemma]: казаться; norm[pos]: VERB | кажется водитель не вовремя видел мячик | |
| км/ч | norm[mystem_gr]: S, abbr; norm[mystem_lex]: км/ч; norm[lemma]: км/ч; norm[pos]: NOUN; all other grammemes on UPOS-layers get deleted | сто км/ч | |
| какой | norm[Case]: Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: APRO11; norm[mystem_lex]: какой; norm[lemma]: какой; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | там шёл какой-то мужик | |
| короче as вводное слово | norm[Degree]: Cmp; norm[mystem_gr]: ADV, parenth; norm[mystem_lex]: коротко; norm[lemma]: коротко; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | короче там шла женщина с коляской | |
| который | norm[Case]: Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: APRO 12; norm[pos]: PRON | этот мальчик ну который там играл с мячиком он | |
| мой, твой | norm[Case]: Gen; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: APRO; norm[mystem_lex]: мой; norm[lemma]: мой; norm[pos]: PRON | я звоню вам с моего телефона | |
| мол as вводное слово | norm[mystem_gr]: PART, parenth; norm[mystem_lex]: мол; norm[lemma]: мол; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ---- | |
| мужик | norm[Animacy]: Anim; norm[case]:Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: S,inform; norm[pos]: NOUN; all other grammemes on UPOS-layers get deleted | мужик побежал на дорогу | |
| наверно, похоже as вводное слово | norm[mystem_gr]: ADV, parenth; norm[mystem_lex]: наверно; norm[lemma]: наверно; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | он наверно этого не знал | |
| никто | norm[Case]: Acc; norm[Gender]: Masc; norm[mystem_gr]: SPRO; norm[mystem_lex]: никто; norm[lemma]: никто; norm[pos] PRON; all other grammemes on UPOS-layers get deleted | я никого не видел | |
| нет | norm[mystem_gr]: PART, parenth; norm[mystem_lex]: нет; norm[lemma]: нет; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | нет не поеду ни за что | |
| ну | norm[mystem_gr]: PART; norm[mystem_lex]: ну; norm[lemma]: ну; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ну что я могу сказать | |
| нужно, можно, надо | norm[mystem_gr]: ADV, praed; norm[mystem_lex]: нужно; norm[lemma]: нужно; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | ----- | |
| ого | norm[mystem_gr]: PART; norm[mystem_lex]: ого; norm[lemma]: ого; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ----- | |
| один | norm[Case]: Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: ANUM; norm[mystem_lex]: один; norm[lemma]: один; norm[pos]: NUM | я видел как один человек позвонил в полицию | |
| окей | norm[mystem_gr]: PART; norm[mystem_lex]: окей; norm[lemma]: окей; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ----- | |
| первый | norm[Case]: Nom; norm[Gender]: Fem; norm[Number]: Sing; norm[mystem_gr]: ANUM; norm[mystem_lex]: первый; norm[lemma]: первый; norm[pos]: NUM | первая машина свернула с дороги на парковку и резко остановилась | stehen lassen |
| пока (conjunction) | norm[mystem_gr]: CONJ; norm[mystem_lex]: пока; norm[lemma]: пока; norm[pos]: SCONJ; all other grammemes on UPOS-layers get deleted | пока она доставала продукты из машины мальчик играл с мячом | |
| пока (leave-taking) | norm[mystem_gr]: INTJ; norm[mystem_lex]: пока; norm[lemma]: пока; norm[pos]: INTJ; all other grammemes on UPOS-layers get deleted | пока пока | |
| потом, затем | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: потом; norm[lemma]: потом; norm[pos]: PRON; all other grammems on UPOS-laysers get delated | потом машины стукнулись | |
| потому, поэтому | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: потому; norm[lemma]: потому; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | потому что водитель был пьяный | |
| раз | norm[Animacy]:Inan; norm[Case]: Nom; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: S,m,inan ; norm[pos]: NOUN; all other grammemes on UPOS-layers get deleted | которая как раз въехала | |
| ранен | norm[Aspect]: Imp; norm[Gender]: Masc; norm[Number]: Sing; norm[Tense]: Past; norm[Variant]: Short; norm[VerbForm]: Part; norm[Voice]: Pass; norm[mystem_gr]: V, tran, praed; norm [mystem_lex]: ранить; norm[lemma]: ранить; norm[pos]: VERB; all other grammemes on UPOS-layers get deleted | никто не ранен | |
| свой | norm[Case]: Acc; norm[Gender]: Masc; norm[Number]: Sing; norm[mystem_gr]: APRO 13; norm[pos]: PRON | он любит свой народ | |
| сзади | norm[mystem_gr]: ADV; norm[mystem_lex]: сзади; norm[lemma]: сзади; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | а сзади как раз машина подъезжает | |
| сзади | norm[mystem_gr]: PR; norm[mystem_lex]: сзади; norm[lemma]: сзади; norm[pos]: ADP; all other grammemes on UPOS-layers get deleted | а сзади неё как раз две машины подъезжают | |
| собакин | norm[case]:Acc; norm[Number]:Plur; norm[mystem_gr]: APRO,poss; norm[mystem_lex]:собакин; norm[lemma]:собакин; norm[pos]:ADJ all other grammems on UPOS-laysers get delated | тётя и дядя я думаю это собакины | |
| спасибо | norm[mystem_gr]: INTJ; norm[mystem_lex]: спасибо; norm[lemma]: спасибо; norm[pos]: INTJ; all other grammemes on UPOS-layers get deleted | ----- | |
| судя | norm[Aspect]: Imp; norm[Tense]: Pres; norm[VerbForm]: Conv; norm[Voice]: Mid; norm[mystem_gr]: V, intr, ger; norm[mytem_lex]: судить; norm[lemma]: судить; norm[pos]: VERB; all other grammems on UPOS-laysers get delated | судя по тому что случилось | |
| там, так, тут | norm[mystem_gr]: ADVPRO; norm[mystem_lex]: там; norm[lemma]: там; norm[pos]: ADV; all other grammems on UPOS-laysers get delated | там женщина шла по дороге | |
| типа | norm[mystem_gr]: PART,parenth; norm[mystem_lex]: типа; norm[lemma]: типа; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | ну типа того | |
| то at the beginning of suboridinate clauses | norm[mystem_gr]: CONJ; norm[mystem_lex]: то; norm[lemma]: то; norm[pos]: SCONJ; all other grammemes on UPOS-layers get deleted | если у вас ещё вопросы возникнут то свяжитесь со мной | |
| то in function to replace sth. | norm[Case]: Nom; norm[Gender]: Neut; norm[Number]: Sing; norm[mystem_gr]: APRO; norm[myste_lex]: тот; norm[lemma]: тот; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | произошло то что мы все предвидели | |
| тоже, только | norm[mystem_gr]: PART; тnorm[mystem_lex]: тоже; norm[lemma]: тоже; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | он тоже вышел из машины | |
| тот, этот, такой | norm[Case]: Dat; norm[Gender]: Fem; norm[Number]: Sing; norm[mystem_gr]: APRO11; norm[mystem_lex]: тот; norm[lemma]: тот; norm[pos]: DET; all other grammemes on UPOS-layers get deleted | по той же дороге ехали ещё две машины | |
| увидев | norm[Aspect]: Perf; norm[Tense]: Past; norm[VerForm]: Conv; norm[Voice]: Act; norm[mystem_gr]: V, tran, ger; norm[mystem_lex]: увидеть; norm[lemma]: увидеть; norm[pos]: VERB; all other grammemes on UPOS-layers get deleted | собака увидев мяч кинулась на него | |
| ф | dipl[language]: rus; norm[mystem_gr]: S,persn; norm[mystem_lex]: ф; norm[lemma]: ф; norm[pos]: PROPN; all other grammemes on UPOS-layers get deleted | ф шестнадцать | |
| хз (хер знает) | norm[mystem_gr]: INTJ, abbr, parenth; norm[mystem_lex]: хз; norm[lemma]: хз; norm[pos]: INTJ | Водители обсуждали ситуацию но полиции не было хз | |
| чуть-чуть | norm[mystem_gr]: ADV; norm[mystem_lex]: чуть-чуть; norm[lemma]: чуть-чуть; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | он чуть-чуть опоздал | |
| щас | norm[mystem_gr]: ADV,inform; norm[mystem_lex]: щас; norm[lemma]: щас; norm[pos]: ADV; all other grammemes on UPOS-layers get deleted | щас приду | |
| это in function to replace sth. | norm[Case]: Nom; norm[Gender]: Neut; norm[Number]: Sing; norm[mystem_gr]: APRO; norm[myste_lex]: этот; norm[lemma]: этот; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | он ему это сказал | |
| это after dash (тире) | norm[mystem_gr]: PART; norm[myste_lex]: это; norm[lemma]: это; norm[pos]: PART; all other grammemes on UPOS-layers get deleted | мама - это самый родной человек на свете | |
| я | norm[case]:Nom; norm[Number]: Sing; norm[Person]: 1; norm[mystem_gr]: SPRO 14; norm[pos]: PRON; all other grammemes on UPOS-layers get deleted | ----- |
5. Comments
1 U-POS and MyStem use partly different features for the POS-tagging of words.
Example: In case of the Russian personal pronoun я U-POS dismisses it to be a pronoun (PRON). Further specifications in U-POS are not given in this context. In contrast to that, MyStem specifies the pronoun.
MyStem dismisses я to be a noun-pronoun (SPRON).
2 In general, all reflexive verbs in Russian can be identified by the verb postfix -ся. But not all verbs which end with the postfix -ся are reflexive verbs. Verbs with a transitive word stem and the postfix -ся are not reflexive verbs, but verbs in passive voice. When in doubt, check the Russian verb by translating it into German. If you can translate the Russian verb with sich... into German, then it is very likely a real reflexive verb and should be marked on norm[Reflex]-layer with Yes and on norm[Voice]-layer with Mid. If that is not possible and you have to translate the verb into German with the aid of the passive construction wird/werden...ge-..., then it is very likely a transitive verb in its passive form. In this case the word gets marked on norm[Voice]-layer with Pas and the norm[Reflex]-layer stays empty .
Example: Книга читается.
Das Buch liest sich. ==> This translation wouldn't make sense (except in fairy-tales), because a book can't
usually read itself.
Das Buch wird gelesen. ==> This translation is more logical than the translation above (if we imagine, that the
context is not a fairy-tale), because the word stem is a transitive verb with the
postfix ending -ся. Therefore, the verb expresses the passive and can be translated
here in that way, that the book gets read by someone, who is unknown or who doesn't
want to be mentioned.
Example: Человек развивается.
Der Mensch wird entwickelt. ==> Развивать is an transitive verb and the postfix -ся could lead to the
conclusion, that in this case we are dealing with the passive voice. Basically,
it is absolutely possible and without the context of course difficult to define.
In view of this, that we don't have a context, orient yourself on the
general meaning of this sentence, which is often used.
Der Mensch entwickelt sich. ==> This is the general meaning of this sentence, which is used quite often. In its
general meaning the verb doesn´t have a passive, instead a reflexive meaning.
This meaning can be preferred in such cases, in which the context doesn't exist
or is not very clear.
3 Transitive verbs are verbs, which govern direct objects (objects in accusative without preposition). Between the verb and the accusative object is no preposition. Only transitive verbs can create the passive voice. The passive voice can be recognized by a word stem of a transitive verb + postfix -ся.
Example: Мальчик читает книгу. Книга читается мальчиком.
Junge (Nom) liest (tran.verb) Buch (Acc.obj. wihtout preposition). Buch (Nom) wird gelesen (pass. voice of a
tran.verb) vom Jungen (Inst).
Intransitive verbs are verbs which govern indirect objects (objects in accusative with preposition or objects in other grammatical cases). Between verbs and object(s) can appear a preposition. The objects can appear in accusative with a preposition, in dative with or without a preposition, in genitive with or without a preposition, in instrumental with or without a preposition and in locative with preposition (objects in locative always stand with a preposition, therefore the Russian locative is called the preposition case). Intransitive verbs can't create the passive voice.
Example: Папа звонит маме. *Мама звонится папой.
Papa (Nom) ruft (intr.verb) an Mama (Dat.). *Mama wird angerufen von Papa.
4 Keep in mind, that not all kinds of adverbs and not all kinds of adjectives can form degrees. The adverb сегодня or the adjective другой can´t form degrees. In these cases you should delate the token on norm[degree]-layer.
5 In this case быть has the function of an auxiliary (Hilfsverb). Therefore, the main act/ main verb of the sentence does not posses быть, but уверен (in combination with быть). On this account the word быть gets defined on norm[pos]-layer as AUX.
6 In this case быть is the main act of the sentence and has therefore the function of the main verb (Vollverb). On this account the word быть gets defined on norm[mystem_lex]-layer and norm[pos]-layer as VERB.
7 The pronoun весь has these grammatical features, if it can be translated as ganz/целый. In these cases весь can be seen more as an adjective, therefore APRO and PRO.
15 The pronoun весь has these grammatical features, if it can be translated as all/aller. In these cases весь gets used to replace a noun or a phrase and to refer back to an element, word or situation, which was already introduced in the discourse before, but the speaker won´t repeat it again, therefore DET and SPRO.
8 In comparison to один, два is defined on norm[mystem_gr]-layer as NUM, because it doesn´t get inflected like an adjective. Therefore, один gets on norm[mystem_gr]-layer ANUM (because it has in inflection features like an adjective) and два gets NUM (because it hasn´t features like an adjective in inflection). Furthermore, in comparison to один два hasn´t a plural paradigma. 9 The word другой is defined on norm[mystem_gr]-layer as APRO, because it gets inflected like an adjective, but has the function of a SPRO to replace other nouns, therfore APRO and ADJ. Furthermore, другой can´t form degrees, therefore the event on norm[degree]-layer should be empty.
10 In this context the verb играть is intransitive, because the Russian preposition c usually requires the instrumental. However, there exist cases, in which играть can be used as a transitive verb.
Example: Вася играет дурака в этом спектакле.
Vasja (Nom) spielt (tran.verb) den Dummen (acc.object without a preposition between verb and object) in diesem
Stück (Loc).
Therefore, all verbs which might have a transitive meaning in other contexts have to be defined as transitive on MyStem layer, even if the verb is used as an intransitive verb in the current context! The reason is, that a verb, which can be used (theoretically) as a transitive verb, gets always treated as a verb with a transitive basic meaning, no matter if this transitive meaning of the verb appears in the current situation or not.
13 The pronoun свой is defined on norm[mystem_gr]-layer as APRO, because it gets inflected like an adjective, therefore APRO.
12 Words like такой or который are defined on norm[mystem_gr]-layer as APRO, because in Russian these pronouns get inflected like adjectives, therefore APRO.
16 то есть is seen as two seperated words, because there is no hyphen (дефис), which combines the two words to one word ==> то is a word for itself and есть is a word for itself. Therefore, each word is seen as an own token, gets an own event and has to be determined grammatically on its own. The same concerns words like потому что or только что. They are seen as two separated words, get own events and have to be grammatically determined on their own.
11 Words like тот or этот are defined on norm[mystem_gr]-layer as APRO, because these pronouns get inflected like adjectives, therefore APRO. These pronouns are defined on norm[pos]-layer as DET, because they have editionally an determinanting (referring) function, because these pronouns refer back to an element, word or situation, which was already introduced in the discourse before, but the speaker won´t repeat it again. Therefore the speaker uses determinating (referring) pronouns.
14 All personal pronouns are defined on norm[mystem_gr]-layer as SPRO and on norm[pos]-layer as PRON. Personal pronouns get defined on norm[mystem_gr]-layer as SPRO, because in Russian these pronouns replace other nouns (существительные), therefore SPRO.
6. Useful links
- If you have problems to decide to which part of speech the current word belongs, then look the word up in the
Национальный корпус русского языка and check their results or solution. But keep in mind that they have analyzed the speech of their participants partly under different conditions and assumptions. - All U-POS features are available here: Universal features part 1 and Universal features part 2
- All MyStem features are available here: MyStem features
- If you have problems to decide whether the current word is a transitive or an intransitive one or if you simply don't know in which grammatical case a word appears, use Викисловарь
Transcription Decisions Turkish
Basics
Format
- create a TextGrid on Praat
- import a TextGrid to EXMARaLDA
Tiers
- speaker tier (e.g TUmo01MT; type: transcription)
- optional tier for segmentation in Intonation Phrases (IP)
- Normalization in EXMARaLDA
Segmentation
- According to Communication Units (CU) Communication_unit__P4_10.12.2018.pdf
- No punctuation
Anonymisation
- Replace name of participant with the respective code (e.g TUmo01MT)
- If whole names or surnames of friends are mentioned, replace with the participant code + _P (e.g. TUmo02FT_P)
- Places that could lead to the identification of a participant (e.g. Atatürk okulunda = Axxx{schoolname} okulunda, Kızılay caddesi = Kxxx{streetname} caddesi)
- if a phone number is mentioned, please anonymize it as {phonenumber}
Transcription
'Unwanted' material (if applicable)
- If this is not possible mark those passages as:
<Q> communication with elicitor </Q>
Merged forms
- Merged forms are transcribed as they are articulated, but with an equal sign linking the merged elements
- Examples from TUmo10MT_isT: n=apıyorsun (= ne yapıyorsun), TUmo11MT_isT: n=aber (= ne haber)
Tag Questions
- tag questions (de mi) do not constitute a separate CU
Reduced syllables
- reduced syllables are transcribed as articulated
- Examples: bi tane (= bir tane), gidiyo (= gidiyorsun) yakıyosun (= yakıyorsun), içbiri (= hiçbiri)
- Use / to mark unfinished words, e.g. “Çarb/ çarptı derken oldu bitti“
Accents and dialects
- pronounced sounds are transcribed as articulated (e.g gardaşım (= kardeşim), but sounds which are not typical for Turkish are not represented.
Pauses
- 0.2 - 1 sec: (-)
- 1-3 secs: (--)
- More than 3 secs: (5.5) to be measured
- Wordinternal pauses are marked as followed: top(-)la - no space between the parts.
Long vocals & consonants
- vocals pronounced longer than normal (under 2sec) are marked with : (e.g. canı:m)
- vocals that are pronounced extremely long (2sec and more) are marked with :: (e.g canı::m)
- also possible for consonants (e.g. tamam:)
- doubling of vocal syllables with % (e.g. ba%ay)
Non-verbal material
-
non-verbal events such as a participant laughing or coughing are noted in square brackets on speaker tier, e.g. [laughing], [whispering, [clears throat], [sighs], [sniffs], [snapsfingers]
-
if participants speak and laugh at the same time, it is noted as: [[laughing]speech]
Uninterpretable material
- uninterpretable material is to be marked as (UNK) on Speaker-tier
- longer than 2secs: (UNK, 2.1)
- assumed content in brackets, each token separated: (assumed) (content)
Hesitation markers / Interjections / Reception markers
- e (short "e") ee (long "ee") ı (short "ı") ııı (long "ııı")
- thinking: "hmm, eem, ımm"
- agreement: "hıhı"
- negation: "ı ıh"
- dissapointment: "tüh"
Foreign language material
- original spelling will be kept.
Proper/Brand names
- Keep conventionalized spelling (e.g. Renault = renault)
Numerals
- Numbers are spelled (e.g 155 = yüz elli beş)
Table of symbols
| Symbols | Meaning |
|---|---|
<Q> araştırmacıyla iletişim </Q> | instances of questions concerning the procedure and/or verbal interventions of elicitators |
| (-) | 0.5 - 1sec |
| (--) | pauses 1-3secs |
| (3.2) | pauses longer than 3secs |
| (UNK) | uninterpretable material |
| (UNK, 2.2) | uninterpretable material longer than 2secs |
| (assumption) | assumed material |
| [gülüşmeler/fısıldaşmalar] | non-verbal material |
| [[gülüşme]konuşma] | non-verbal & verbal event |
| : | unusually long vocal or consonant (under 2secs) |
| :: | unusually long vocal or consonant (longer than 2secs) |
| = | merged forms |
| / | interruption of a word |
| % | doubled syllables |
| {...} | specification of an anonymised place |
Turkish Normalization
Basics
- Orthographic normalization.
- No changes in grammar (case, tense etc).
- Pauses are deleted on a norm layer.
- Non-verbal material (laughing, coughing) is deleted on a norm level.
Anonymized material
-
Participant's codes are deleted on a norm layer.
-
Anonymized material should be left the same way as on a dipl layer (e.g., kxxx{streetname}da).
- if an anonymized token is followed by an ending only, the ending should be placed in one box;
- if an anonymized token is followed by a word, like sokakta, mahallede etc, these words are placed in the next box.
Capitalization
- Proper names are capitalized on a norm layer.
- Names of countries, nations are capitalized (e.g., Almanya, Almanlar);
- Names of days, months are capitalized (e.g., Salı, Ekim);
- Nouns like sokak, cadde, mahalled are capitalized in case they are used together with proper names (e.g., Necatibey Sokağı'nda)
- German nouns are capitalized (e.g., Auto)
- For the capitalization norms of the word "Allah", check TDK Allah (Atasözü, deyim ve birleşik fiiller)
- If a common noun is capitalized when it is not placed at the beginning of a sentence (e.g., Futbol Topu), on a norm level it should be corrected as (e.g., futbol topu).
- if the whole text or some of its parts was written in CAPS, it should be changed to lower case except where Turkish standard orthography demands capitalization.
Apostrophe
- Proper names (e.g., Starbucks), country names (e.g., Almanya) and nouns like sokak, cadde, mahallede require an apostrophe in case they are used together with proper names and used in a dative, accusative, or locative cases (e.g., Necatibey Sokağı'nda);
Dates and Numbers
- Code 'ef on altı'/ 'fe on altı' is represented as F16 (written in one box);
- If a date is written as 15.10.2018, it stays as 15.10.2018 on a norm level;
- But if a date is spelled out (e.g., on beş ekim), the day is represented with numbers, but the month is spelled out and capitalized (e.g., 15 Ekim).
Cancellations, Repairings
- If a canceled/repaired token is a meaningful word, then it stays on a norm level, but without a slash (e.g., çarpma/ çarpıştı --> çarpma çarpıştı -- in separate boxes).
- if a canceled/repaired token is a word, but is not meaningful according to the context, we delete it on a norm layer (e.g., arı/ araba geliyordu --> araba geliyordu);
- if a canceled/repaired token is not a word (e.g., kö/ köpek havladı), we delete it on a norm layer (e.g., kö/ köpek havladı --> köpek havladı).
Assumed material
- if on a diplomatic layer, a word is placed in parentheses as assumed material, we leave the parentheses out and keep only the word itself (e.g., (muhtemelen) --> muhtemelen);
- if the assumed material is not a word (e.g., trafik kasağı), we try to guess the closest meaningful word and normalize it as trafik kazası.
- if the meaning of the assumed material cannot be guessed, we leave it empty on a norm layer.
- orphographic mistakes (especially in written data) are corrected (for example, qma -> ama, cüpike --> köpek).
Foreign Material
- Foreign material is normalized according to the rules of the language it is taken from.
Hesitation Markers
| dipl layer | norm layer |
|---|---|
| e, ee, eee | e |
| ı, ıı, ııı | e |
| em, hm | e |
Punctuation
- Each punctuation mark is placed in a separate box.
- A triple-dot punctuation mark (...) is placed in one box.
Material which is not found in TDK (please update the list during the normalization)
| dipl layer | norm layer |
|---|---|
| laylaylom/lay lay lom | laylaylom |
| boooah | boah |
| off | of |
Long Vocals & Consonants
- Long vocals & consonants (may they be represented with a colon: or with the help of two vowels), the words are spelled according to the orthographic norms (e.g., ya: --> ya)
Emojis
- Emojis are represented on a norm layer as they are on a dipl layer;
- One emoji is placed into one box.
Dipl[lang] Layer
- The code of Turkish is tur
- if we see UNKNOWN instead of tur on a dipl[lang] layer, we change it into tur manually.
- we delete the language code in case of pauses, non-verbal material (like laughing, coughing), punctuation marks.
- we change the language code in case of foreign material BUT: change the code of the language only in case when the word has not been adopted into Turkish yet. E.g., hasar would be still tur, or tişört is tur. But bye bye is eng.
- delete language code for participants' codes
| code | language |
|---|---|
| tur | Turkish |
| deu | German |
| eng | English |
| ara | Arabic |
| kur | Kurdish |
Dipl[line] and dipl[message] Layers
- disregard these layers.