Overview of Annotations
The RUEG corpus is a multi-layer corpus of both written and spoken language.
We use several annotation formats in the process of annotation, but all annotations, except for the dependency annotations, are part of the
EXMARaLDA file in the exb directory.
In addition to the editable EXMARaLDA format, the corpus is also converted to the ANNIS format (annis directory) for search and visualization.
Dependencies between annotation layers
Most annotation layers depend on other annotations. This can to lead to complex dependencies, as visualized by the following graph:
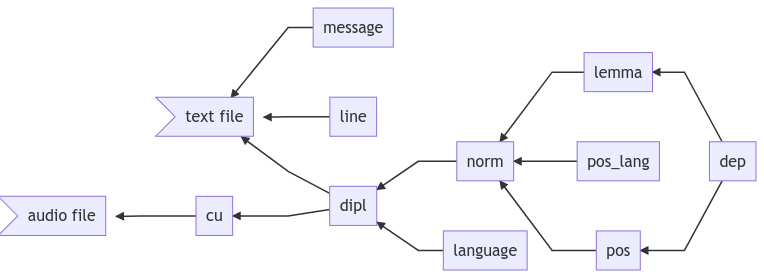
Meta data fields
DISCLAIMER: All sub-1.0 releases may feature inconsistencies in the formatting of the meta data values or show incompleteness of metadata.
In addition to the annotation layers, each document has also meta data fields which are stored in the .meta file next to each EXMARaLDA file.
The meta data is also included in the ANNIS format.
| field name | type | description |
|---|---|---|
| speaker-id | String | |
| formality | String | informal/formal |
| mode | String | spoken/written |
| speaker-bilingual | Boolean | yes/no |
| elicitation-session | Number | 1 (monolinguals, bilinguals in first session) 2 (bilinguals in second session) |
| elicitation-language | String | Language that is elicited from the speaker |
| elicitation-country | String | |
| elicitation-order | Number | 1-8 |
| elicitator-good-id | String | project- and people-number of "good cop" |
| elicitator-bad-id | String | project- and people-number of "bad cop" |
| elicitation-date | String | 2018-XX-XX |
| transcriber-id | String | comma-separated list of project- and person-number XX-XX |
| normalizer-id | String | comma-separated list of project- and person-number XX-XX |
| annotator-id | String | comma-separated list of project- and person-number XX-XX |
| speaker-language-s | String | Languages as given by the participants and separated by comma |
| speaker-age-group | String | children/adolescents/adults |
| speaker-gender | String | m/f/d |
| speaker-age | Number | two-digit number year |
| speaker-AoO | Number | Age Of Onset in years (two-digits) |
| speaker-AoO-answer | Number | complete, but anonymized answer string |
| speaker-personality-score-X | Number | Personality score (1-7) for each of the questions 1-6 of the personality test |
| speaker-extravert-score | Number | aggregated extravert score |
Meta data fields new in 0.3.0
| field name | type | automatically retrievable from questionnaire | description / comments |
|---|---|---|---|
| speaker-region-of-birth | String | text value only | This and the following meta key are retrieved as place of birth, from which you are supposed to extract the region (e. g. "Bavaria", "North Carolina", "Krasnoyasrk", "Aegean Islands", "Central Anatolia", you might prefer the term federal state or province ) and/or the country. For privacy reasons please do not provide the city or even more detailed information. |
| speaker-country-of-birth | String | text value only | See above. |
| speaker-age-of-immigration | Number | yes | Age of arrival in country of majority language in years. Single digit. For the age in years and months, use one of the following options: for instance, for 3 years 6 months, you can write 3.5 or 3;6. |
| speaker-education-degree | String or Number | yes | Categorical values, provided by questionnaire. Please be careful with the adolescents: many of them selected high school as their highest degree completed but in fact they did not complete it yet. So we need to look at "grade. School year" to see if the adolescent is in high school or in college. |
| speaker-employment | String | yes | Categorial values, provided by questionnaire. |
| speaker-dialect-s | List of strings | yes | List of dialects spoken (comma-separated). |
| speaker-language-instructed-1 | String | yes | A language the participant was instructed in. More languages possible (2, 3, ...). |
| speaker-language-instructed-1-duration | Number | no | Number of YEARS (other unit prefered?) the participant was instructed in language 1. As with the fields concerning age, you can write 3.5 or 3;6. |
| speaker-parent-1-... | |||
| speaker-parent-2-... | |||
| speaker-parent-3-... | |||
| speaker-parent-4-... | |||
| speaker-parent-1-name | String | yes | "Mother", "Father", "Sister", "Brother", etc. Capitalization does not matter, leave the words as they were originally written. Needs to be anonymized. |
| speaker-parent-1-country-of-birth | String | textual value | Please extract the name of the country from the given answer. Delete any more precise information. |
| speaker-parent-1-region-of-birth | String | textual value | Please extract the name of the region from the given answer. Delete any more precise information. |
| speaker-parent-1-degree | String or Number | yes | As above, highest degree, but for parent / adult. |
| speaker-parent-1-profession | String | yes | Profession of parent / adult. |
| speaker-parent-1-employment-institution | String | yes | Current employment (institution, category) of parent / adult. Might need anonymization. Note that sometimes only position or institution is derivable from the answer, so n/a should be used for unavailable meta values. |
| speaker-parent-1-employment-position | String | yes | Current employment (position, category) of parent / adult. Might need anonymization. Note that sometimes only position or institution is derivable from the answer, so n/a should be used for unavailable meta values. |
| speaker-parent-1-language-home-1 | String | yes | Language spoken at home by parent / adult (to anybody). Capitalize the language!! |
| speaker-parent-1-language-home-2 | String | yes | Language spoken at home by parent / adult (to anybody). |
| speaker-parent-1-language-home-3 | String | yes | Language spoken at home by parent / adult (to anybody). |
| speaker-parent-1-dialect-s-home | List of strings | yes | Dialects spoken at home by parent / adult (to anybody). Capitalize the dialect!! |
| speaker-env-1-... | Those values are for adults in current environment, but also include the parents again. | ||
| speaker-env-2-... | Therefore we might not have to use all of them. | ||
| speaker-env-3-... | All values meta fields for parents have to be repeated for adults in environment. | ||
| speaker-env-4-... | |||
| speaker-shares-home-with-env-1 | Boolean | Whether or not the speaker lives together with the respective adult in their environment. | |
| speaker-shares-home-with-env-2 | Boolean | ||
| speaker-shares-home-with-env-3 | Boolean | ||
| speaker-shares-home-with-env-4 | Boolean | ||
| speaker-frequency-of-visits | String | as text | How often the participant visits the country where the heritage language is spoken. |
| speaker-self-assessment-hl-oral-understanding | String or Number | yes | Self assessment by participant of oral understanding in heritage language. |
| speaker-self-assessment-hl-written-understanding | String or Number | yes | Self assessment by participant of understanding of written text in heritage language. |
| speaker-self-assessment-hl-oral-production | String or Number | yes | Self assessment by participant of oral production skills in heritage language. |
| speaker-self-assessment-hl-written-production | String or Number | yes | Self assessment by participant of written production in heritage language. |
| speaker-self-assessment-hl-native | Boolean | yes | Does the participant consider him-/herself a native speaker of the heritage language. |
| speaker-languages-used-regularly-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks regularly to adult 1 (environment). |
| speaker-languages-used-often-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to adult 1 (environment). |
| speaker-languages-used-rarely-to-env-1 | List of strings | yes | Languages (comma-separated) the participant speaks rarely to adult 1 (environment). |
| ... | |||
| speaker-languages-used-regularly-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks regularly to parent 1. |
| speaker-languages-used-often-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to parent 1. |
| speaker-languages-used-rarely-to-parent-1 | List of strings | yes | Languages (comma-separated) the participant speaks often to parent 1. |
| ... | |||
| parent-1-languages-used-regularly-to-speaker | |||
| parent-1-languages-used-often-to-speaker | |||
| parent-1-languages-used-rarely-to-speaker | |||
| env-1-languages-used-regularly-to-speaker | |||
| env-1-languages-used-often-to-speaker | |||
| env-1-languages-used-rarely-to-speaker | |||
| ... | |||
| speaker-habits-video-consumption-hl | String | yes | How often does the participant consume videos in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-audio-consumption-hl | String | yes | How often does the participant consume auditive media in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-text-production-hl | String | yes | How frequently does the participant produce text in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-text-consumption-hl | String | yes | How often does the participant read in the heritage language. Can be delivered for other languages as well. |
| speaker-habits-uses-native-script | String | as text | This needs some additional thought. A textual answer is delivered an we still need to think of useful value set. P2: we are replacing unhelpful answers like "script", "keyboard", and "alphabet" with* n/a.* |
| speaker-habits-messenger | String | yes | Which text messenger does the participant mostly use. |
| speaker-habits-activities | String | yes | Which activities does the participant exercise. Needs privacy check, could maybe be dropped and only languages are kept. |
| speaker-habits-activity-language-s | String | yes | Languages used during those activities. |
| elicitation-ease-formal | Boolean | yes | Was it easy for the participant to image herself in the formal situation. |
| elicitation-ease-informal | Boolean | yes | Was it easy for the participant to image herself in the informal situation. |
| elicitation-issues-with-smartphone | Boolean | yes | Did the participant face any issues dealing with the smartphone during elicitation. |
| elicitation-issues-with-smartphone-text | Boolean | yes | Text answer describing the issues with the smartphone. Empty if no issues occured. |
| speaker-habits-smartphone-type | String | yes | Not sure that is necessary, but we have it. |
cu (Communication Unit)
Value set: open
Segmentation and transcription of Communication Units For spoken data, the start and the end of the CUs are manually aligned with the audio.
See the transcriptions guidelines for details.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | manual | Transcription | exb |
dipl (Tokenization)
Value set: open
Automatic tokenization of the text into words.
- as defined by the TreeTagger tokenization script
- extra handling for emojis and pauses
Language-specific differences
- language specific abbreviations
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | TreeTagger | exb |
norm (corpus-wide normalization)
Value set: open
A common normalization that is the same for written and spoken data. This allows a search across registers.
- segmented into graphemic words
- emojis are a single word
- text messsage acronyms are treated as single word
- punctuation is considered a token if not part of an emoji
- following standard orthography
- no word order corrections
- no grammatical corrections
Language-specific differences
- script is normalized to language standard
- each language decided on
- orthographic standard
- clitics
- script
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Copy base text | exb |
| 2 | manual | Normalize | exb |
lemma (Lemmatization)
Value set: open
Lemmatization based on the normalization (norm).
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | lemmatization (part of the POS-tagging) | exb |
| 2 | manual | correction | exb |
pos (Universal part of speech)
Value set: closed
Part of speech annotation using the Universal POS tags.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Automatic POS tagging | exb |
pos_lang (Language specific Part of speech)
Value set: closed
Part of speech annotation with a tag-set for each language.
- there is one common tag-set for each language
- text message acronyms get their own tag manually (or if the tagger supports it, automatically)
Different tagsets are used for each language:
| language | tag set | reference |
|---|---|---|
| English | British National Corpus / Claws 4 | Leech et al. 19941 |
| German | STTS 2.0 | Westpfahl 20142 |
| Russian | MyStem tag set | Segalovich 20033 |
| Turkish | MULTILIT tag set | Schroeder et al. 20154 |
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Automatic POS tagging with tool | exb |
| 2 | manual | correction | exb |
language (Language/Foreign Material)
Value set: closed
Describes the language.
- per-token
- ISO three letter language code
- every token has this category assigned
- no dialects
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | Fill out default language | exb |
| 2 | manual | Mark foreign material | exb |
message (Chat Message span)
Value set: natural numbers
Span annotation for each message in the chat. Contains its consecutive number.
line (Chat Message line)
Value set: open
Span annotation with the chat message text as content.
Processing steps
| # | type | step | output format |
|---|---|---|---|
| 1 | automatic | exb |
dep (Universal Dependencies)
Value set: closed
Automatic Universal Dependency parsing.
Processing steps
| # | type | step | output format | |
|---|---|---|---|---|
| 1 | automatic | UD Parsing | CoNLL |
Leech, Geoffrey, Roger Garside, and Michael Bryant. 1994. “CLAWS4: The Tagging of the British National Corpus.” In COLING 1994 Volume 1: The 15th International Conference on Computational Linguistics. Vol. 1.
Westpfahl, Swantje. 2014. “STTS 2.0? Improving the Tagset for the Part-of-Speech-Tagging of German Spoken Data.” In Proceedings of Law Viii-the 8th Linguistic Annotation Workshop, 1–10.
Segalovich, Ilya. 2003. “A Fast Morphological Algorithm with Unknown Word Guessing Induced by a Dictionary for a Web Search Engine.” In MLMTA, 273–80. Citeseer.
Schroeder, Christoph, Christin Schellhardt, Mehmet-Ali Akinci, Meral Dollnick, Ginesa Dux, Esin Işil Gülbeyaz, Anne Jähnert, et al. 2015. “MULTILIT.” Universität Potsdam. https://publishup.uni-potsdam.de/opus4-ubp/frontdoor/index/index/docId/8039.