tiger1 > tiger2 - A Quick Primer for TigerXML Users
Since <tiger2/> is very closely related to the original TigerXML (a.k.a. tiger1), this page gives a quick primer concentrating on the differences between the two formats for TigerXML veterans. The following example snippets will concentrate on the analysis of the sentence:
I wanna put up new wallpaper.and the different ways of representing its structure that <tiger2/> offers. We assume the basic analysis in the figure below as a starting point, which would also be representable in TigerXML.
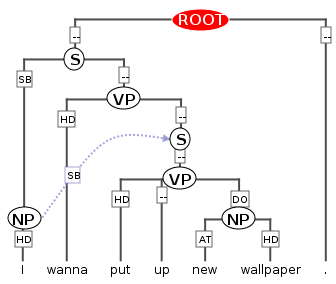
Basic syntax tree for 'I wanna put up new wallpaper' (visualization in ANNIS)
The <head> area
The function of the head area remains, as in the original TigerXML, to specify metadata and declare the valid range of annotations available in the text.
Metadata
The only difference between TigerXML and <tiger2/> at the top of the document is in the corpus element. The id attribute of the corpus or subcorpus must carry the xml: namespace (however see the complete releases on multiple subcorpora and subcorpus recursion). The corpus must also specify the format version used, as shown below.
| tiger2 | tiger1 |
|---|---|
Annotation Declaration
There are several differences in the way annotations are declared in <tiger2/>:
- The declaration is binding and is evaluated for validation purposes by the API
- Attribute names and values can be optionally be bound to ISOCat to define their content
- Features of nodes and edges are all defined using the <feature> element; there is no special <edgelabel> element
- domain names are all declared in lower case, to match the respective elements
| tiger2 | tiger1 |
|---|---|
In addition, <tiger2/> allows the definition of types for terminals, non-terminals and edges:
- It is possible to define secondary edges as in TigerXML, but also dependecy edges or other types of edges
- Different types of terminals (e.g. PRO forms) or non-terminals (e.g. compounds) can be defined
- Each element type can carry its own unique subset of annotations (thus non-terminal compounds may be given a lemma attribute while syntactic categories are not)
Here are some examples of dependency edge, compound, and morpheme declarations (however, for units below the word level we recommend interfacing with MAF, see below)
| tiger2 - dependency declaration |
|---|
| tiger2 - compounds and morphemes |
|---|
The <body> area
The body area if filled with <s> elements, which define the basic segments of the analysis (usually sentences). The <s> elements can look somewhat different depending on whether the primary text is present inline within the document, or standoff in another XML file, e.g. using the interface to MAF (see below). Inline text is specified using the 'word' attribute, which has to be declared in the <head> area as above. References to external text sources are given through the 'corresp' attribute, which must contain a valid URI and cannot be declared (since their value is always defined as a URI).
The <graph> element
An <s> element may contain one or more graphs. Each graph contains terminals and non-terminals, as in TigerXML. The attributes 'root' and 'discontinuous' are optional and are not validated (i.e. it is not checked whether or not the root of the graph is indeed the specified element). They are mainly used for compatibility with TigerXML and in order to speed up processing in certain scenarios.
Standoff Corpora
In standoff corpora the terminals in the <s> element refer to an external xml file as the source of their textual reference. In the following example, this is a MAF document, which is given below on the right for reference. Note that in this case, pos and lemma annotation has been relegated to the MAF document, so that the <tiger2> terminals have no further annotations except the source, given by the 'corresp' attribute. The MAF <wordForm> element handles the grouping of subtokens into larger, syntactically analyzable units.
Also note the use of 'xml:id' and 'target' instead of TigerXML 'idref'. The value of 'target' is a URI specified with a hash (#), and can also refer to nodes in other <s> units (e.g. for coreference annotation). The use of URIs ensures documents can be validated and evaluated using standard XML conformant tools.
| example.standoff.tiger2 | example.standoff.maf.xml |
|---|---|
Inline Corpora
Inline corpora look are more simliar to the original TigerXML, using the 'word' attribute to specify the underlying text. The main differences are in the use of typing in nodes and edges, as well as the use of the 'target' attribute instead of 'idref'. The example below shows the simultaneous use of constituency and dependency trees with typed edges, along with coreference edges and a special terminal type for PRO elements. Such extensions can be defined by the users, but must be declared in the <annotation> element in <head>. An entire document with head and body is given below (for all complete documents shown here and other use cases, see the downloads on the examples page).
| example.inline.coref.pro.tiger2 |
|---|