

Suchebenen
Im Folgenden erhalten Sie einen kurzen Überblick über die Architektur der Deutschen Diachronen Baumbank. Detailliertere Informationen über den Aufbau und die Annotationen erhalten Sie unter dem Menüpunkt "Dokumentation der Korpora".
Eine Einführung in die Korpussuche erhalten Sie unter dem Menüpunkt "Suchszenarien".
Die Subkorpora der Deutschen Diachronen Baumbank enthalten folgende Annotationsebenen:
Darstellung der Edition (Ebene "edition")
Auf der Ebene "edition" können Wortformen eingesehen (und theoretisch gesucht) werden, wie sie in der Textedition vorliegen. Es wurde versucht, die Eigenheiten der vorliegenden Texteditionen so originalgetreu wie möglich darzustellen. Auf der Ebene "tok" werden die Formen der Editionsebene nach bestimmten Kritierien (s.u. bzw. in der ausführlichen Dokumentation) normalisiert. Diese bildet die wichtigste Referenzebene im Korpus, die so genannte Token-Ebene. Da die Editionsebene nicht granularer sein kann als die Tokenebene (sie kann keine Subtoken enthalten), werden Subtokeneinheiten durch das Zeichen "|" getrennt dargestellt. Für die Repräsentationen der individuellen Texteditionen, vgl. die entsprechenden Dokumentationen (s.u.).
![]()
Bsp. f. einen althochdeutschen Satz, dargestellt auf der Editionsebene
Da sich die Normalisierung nach der Beschaffenheit der jeweiligen Edition richtet, werden die unterschiedlichen Normalisierungen im textspezifischen Teil (s.u.) behandelt.
Erstellung einer normalisierten Wortformebene (Ebene "tok")
Individuelle Wortformen der unterschiedlichen Sprachstufen können am besten auf der normalisierten Wortformebene gesucht werden. Diese Ebene trägt den Namen "tok". Die unterschiedlichen Texteditionen sind sehr uneinheitlich bezüglich vieler Faktoren (Spatiensetzung, Graphemsysteme usw.).
Um Suchen über die unterschiedlichen Korpora hinweg möglich und intuitiv zu machen, wurden die Editionsebenen mit einer normalisierten Ebene aligniert. Die normalisierte Ebene bildet die Tokenebene des Korpus und wird deshalb mit "tok" bezeichnet.
![]()
Bsp. f. die Normalisierung von Wortformen im althochdeutschen Subkorpus: Es werden Wortformen aufgelöst (biuuege --> bi uuege), zusammengeführt (ga hortun --> gahortun), Zeilentrennungen aufgehoben (siz|/|cente --> sizsente), Abkürzungen aufgelöst (i?s --> iesus), Sonderzeichen wie "•" entfernt.
Da sich die Normalisierung nach der Beschaffenheit der jeweiligen Edition richtet, werden die unterschiedlichen Normalisierungen im textspezifischen Teil (s.u.) behandelt.
Lemmatisierung (Ebene "lemma")
Die Suchebene für Lemmata trägt die Bezeichnung "lemma". Um nach unterschiedlichen Wortformen, die zu derselben Grundform gehören, suchen zu können, wird jeder Wortform auf der normalisierten Ebene ein Lemma (=eine Grundform) zugeordnet. Dieses ist (per Konvention) bei Verben der Infinitiv und bei den nominalen Einheiten die erste Person Singular (ggf. Maskulinum, stark).
Bei diesem Schritt findet zudem eine orthographische Normalisierung nach einer für die entsprechende Sprachstufe geltenden Norm statt, die durch ein entsprechendes Referenzwörterbuch gegeben wird. Somit ist es auf den unterschiedlichen Ebenen möglich, entweder nach Formen zu suchen, welche denjenigen der uns vorliegenden Textedition entsprechen (dies ist auf der entsprechenden Editionsebene möglich). Möchte man jedoch etwas intuitiver nach Wortformen ohne editionsspezifische Schreibungen oder Sonderzeichen suchen, so kann man auf der Lemma-Ebene Grundformen verwenden, die den Einträgen des für die jeweilige Sprachstufe gültigen Referenzwörterbuchs entsprechen.

Bsp. f. die Lemmatisierung von Wortformen im althochdeutschen Subkorpus: Zum einen werden Wortformen auf eine Grundform zurückgeführt (plinte --> plint), zum anderen werden individuelle orthographische Repräsentationen gemäß Wörterbuch (hier: Schützeichel 1995) normalisiert (sizcen --> sizzen).
Wortartentagging (Ebene "pos")
Jeder Wortform auf der Normalisierungsebene wird ein Tag für eine Wortart zugeordnet. Das verwendete Tagset ist dasjenige, welches sich im Deutschen am besten durchgesetzt hat bzw. für die meisten Korpora verwendet wird – das STTS (Stuttgart-Tübingen Tagset). Die verwendeten STTS-Tags können im TIGER-Annotationsschema auf S. 121ff oder in der Liste der STTS-Tags für TIGER und DDB eingesehen werden (die dort beschriebenen Änderungen an der ursprünglichen Tagliste gelten auch für die DDB-Korpora).

Beispiel für die Zuordnung von Wortartentags zu den normalisierten Wortformen im althochdeutschen Subkorpus
flexionsmorphologisches Tagging (Ebene "morph")
Bei stark flektierenden Sprachen wie den hier beschriebenen Sprachstufen des Deutschen liegt eine flexionsmorphologische Annotation auf der Hand. Die Berücksichtigung dieser Annotationsebene kann bei der Suche nach bestimmten grammatischen Kategorien von erheblichem Nutzen sein.
Die Richtlinien für das flexionsmorphologische Tagging sind orientieren sich weitestgehend an den Richtlinien gemäß dem Tiger-Morphologieschema. Die im Projekt verwendeten flexionsmorphologischen Tags sind im DDB-Morphschema dokumentiert.
Generell wird den flektierbaren Wortarten ein Wert gemäß ihrem aktuellen Flexionsstatus im Satz zugewiesen. Generell nicht flektierbare Wortarten erhalten keine Annotation ("--").

Beispiel für die morphologische Annotation der normalisierten Wortformen im althochdeutschen Subkorpus
Für jede flektierbare Wortart ist die Annotation einer bestimmten Anzahl von Flexionskategorien vorgesehen, die durch "." voneinander getrennt werden. Wenn in einem bestimmten syntaktischen Kontext eine Kategorie nicht bestimmt werden kann, wird der Wert "*" vergeben. Unflektierbare Wörter, die einer generell flektierbaren Wortart angehören, erhalten für alle Flexionskategorien "*" (z.B. allerlei →"*.*.*").
Syntaxannotation (Ebenen "cat" und "func")
Die syntaktische Annotation erfolgt durch dir Erstellung von Baumgraphen, die Knoten und Kanten enthalten. Die Knoten entsprechen syntaktischen Phrasenkategorien, die Kanten syntaktischen Funktionen und Bindungsrelationen. Somit verbindet die syntaktische Annotation eine Phrasenstrukturbeschreibung (mit Kategorien wie "AP" oder "NP" für "Adjektiv-" bzw. "Nominalphrase" bzw. Kantenlabels wie "HD" für "Kopf") mit einer dependenzgrammatischen Beschreibung (z.B. durch das Kantenlabel "OA" für "Objekt, Akkusativ").
Das Annotationsschema kann erheblich von aktuellen generativen oder dependenziellen Syntaxformaten abweichen. Es erhebt keinen Anspruch auf eine adäquate modellgebundene Beschreibung, sondern soll bei der Suche nach unterschiedlichen syntaktischen Konstruktionen möglichst einheitlich und funktional sein.
Das zugrunde liegende Annotationsschema für die syntaktische Annotation ist das Tiger-Annotationsschema.
Bei der syntaktischen Annotation der verschiedenen Sprachstufen des Deutschen wurden hinsichtlich dieser Vorlage keine Änderungen an den Listen für Knoten- und Kantenlabels vorgenommen, um Einheitlichkeit und Vergleichbarkeit mit der größten deutschen Baumbank zu gewährleisten.
Eine Auflistung der in DDB verwendeten Knotenkategorien (mit kurzen Erläuterungen) befinden sich in der DDB-cat-Liste, eine Auflistung der in DDB verwendeten Kantenkategorien befindet sich in der DDB-func-Liste.
Bestimmte syntaktische Kategorien, Funktionen oder Relationen, die spezifisch für eine bestimmte Sprachstufe sind, werden nicht explizit (durch Vergabe von entsprechenden Knoten- oder Kantenlabels) gelabelt, sondern werden implizit durch distinktive Annotationskonventionen beschrieben. Die Annotationsrichtlinien für die einzelnen Sprachstufen sind in den jeweiligen detaillierten Richtlinien beschrieben.
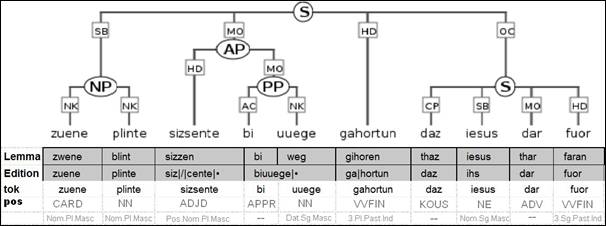
Beispiel für die syntaktische Annotation im althochdeutschen Subkorpus